Work session
2023-10-06 Fri
Datasaurus
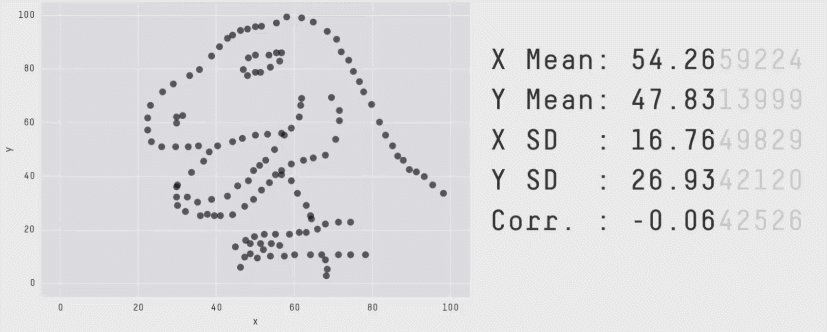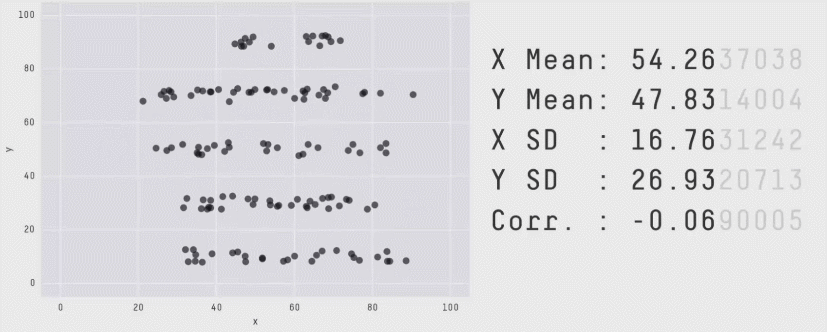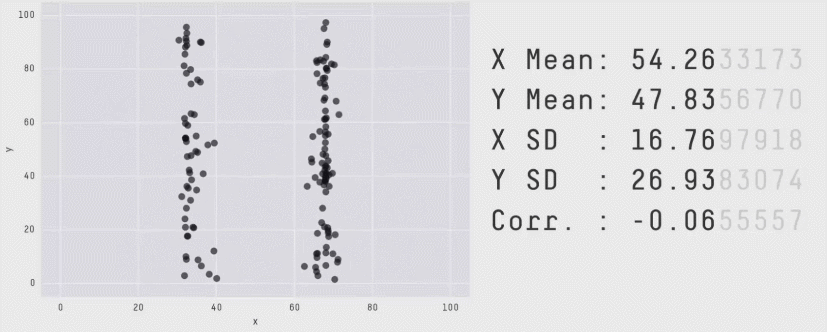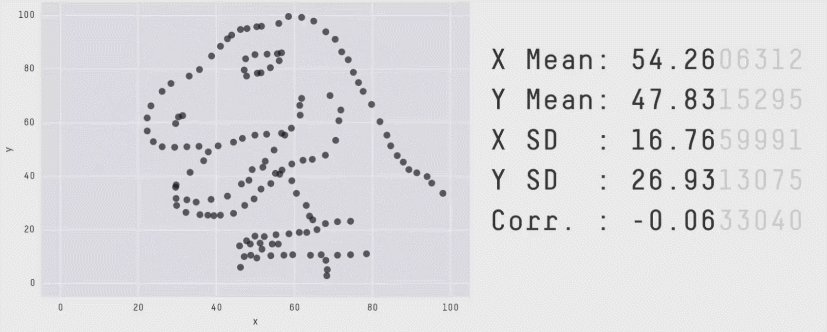 See also this supplementary page on plotting and degrees of freedom.
See also this supplementary page on plotting and degrees of freedom.
Illustration

Table 3 from Simmons et al. (2011)
First, notice that in our original report, we redacted the many measures other than father’s age that we collected (including the dependent variable from Study 1: feelings of oldness). A reviewer would hence have been unable to assess the flexibility involved in selecting father’s age as a control. Second, by reporting only results that included the covariate, we made it impossible for readers to discover its critical role in achieving a significant result. Seeing the full list of variables now disclosed, reviewers would have an easy time asking for robustness checks, such as “Are the results from Study 1 replicated in Study 2?” They are not: People felt older rather than younger after listening to “When I’m Sixty-Four,” though not significantly so, F(1, 17) = 2.07, p = .168. Finally, notice that we did not determine the study’s termination rule in advance; instead, we monitored statistical significance approximately every 10 observations. Moreover, our sample size did not reach the 20-observation threshold set by our requirements.
The redacted version of the study we reported in this article fully adheres to currently acceptable reporting standards and is, not coincidentally, deceptively persuasive. The requirement-compliant version reported in Table 3 would be—appropriately—all but impossible to publish.
Findings
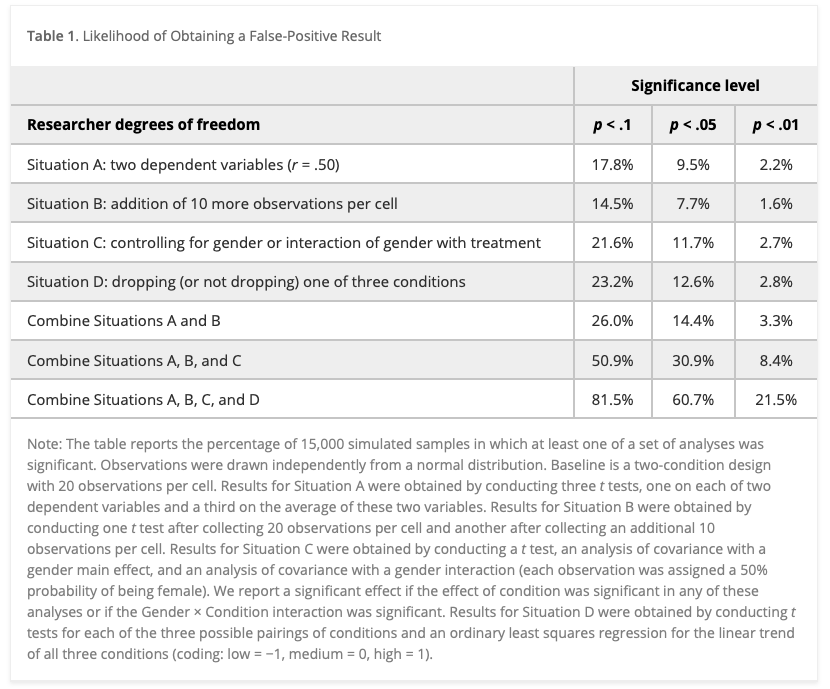
Table 1 from Simmons et al. (2011)
- Researcher choices inflate false positive rates.
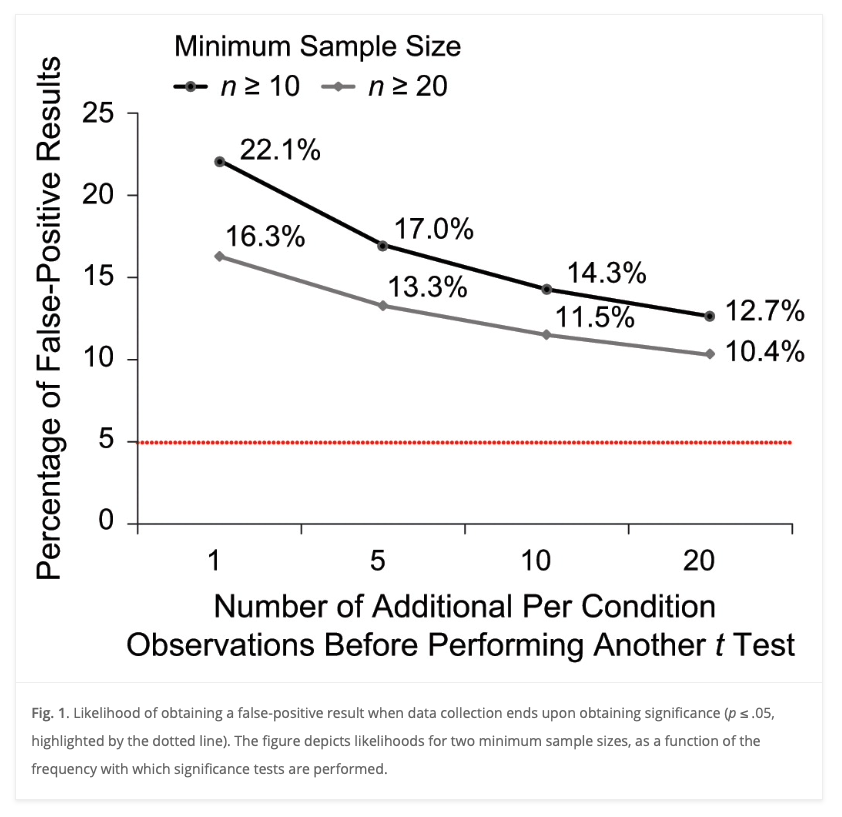
Figure 1 from Simmons et al. (2011)
- Collecting more data after analyzing a small initial sample inflates the false positive rate.
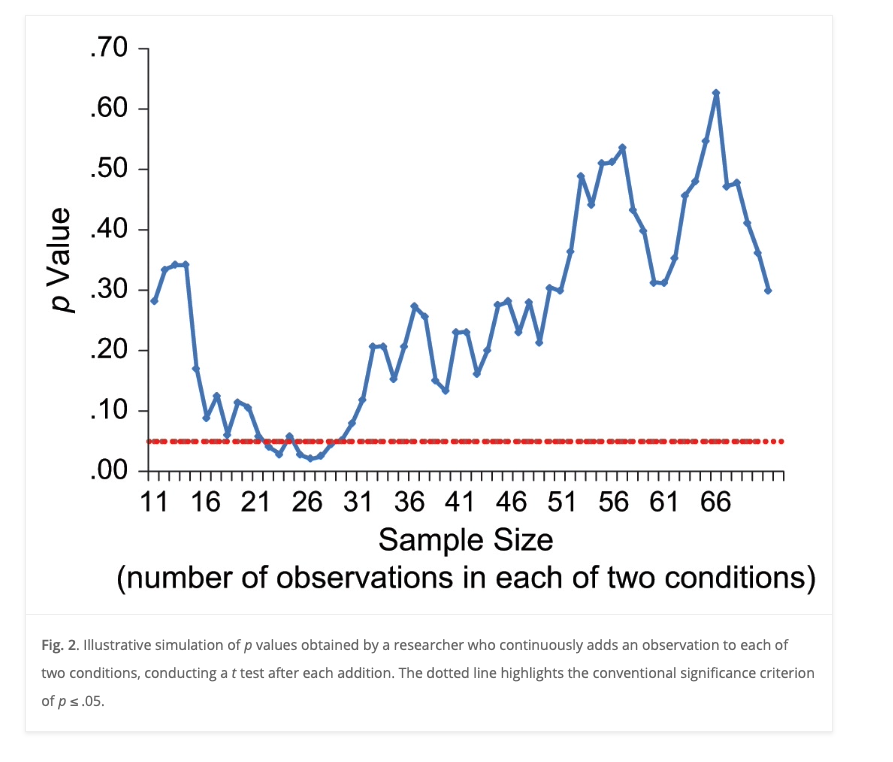
Figure 2 from Simmons et al. (2011)
- Just because a statistical test met the criterion threshold with a small sample doesn’t mean it will do so with larger samples.
Recommendations

Table 2 from Simmons et al. (2011)