This document summarizes an analyis of the p-hacking exercise. In it, we gather data about what individual students did and try to make sense of it.
Quantitative analysis
It often saves typing to load a set of commands into memory. In R, groups of useful commands are called ‘packages’. We can load a set of useful packages into memory by issuing the following command:
library(tidyverse)
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.1 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.1
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
Note
If you are interested in a career related to data science, tidyverse is a very powerful set of tools you will want to know more about.
Then I download the Google Sheet to a directory/folder called csv/ using the file name p-hacking-fa23.csv.
googledrive::drive_download(file ="PSYCH 490.012 2024 Fall P-hacking", path ="csv/p-hacking-fa24.csv", type ='csv', overwrite =TRUE)
File downloaded:
• 'PSYCH 490.012 2024 Fall P-hacking'
<id: 1NXcBrI_bMP_wFi1BurCS5WGppr9HWBiF5ulh7ch61MU>
Saved locally as:
• 'csv/p-hacking-fa24.csv'
Note
What does CSV mean?
Why are CSV files often used in data analysis?
One answer is that CSV files are inter-operable and largely reusable, two of the characteristics recommended for sharing data under the FAIR principles (Wilkinson et al., 2016).
Next, I read the CSV file using the read_csv() function.
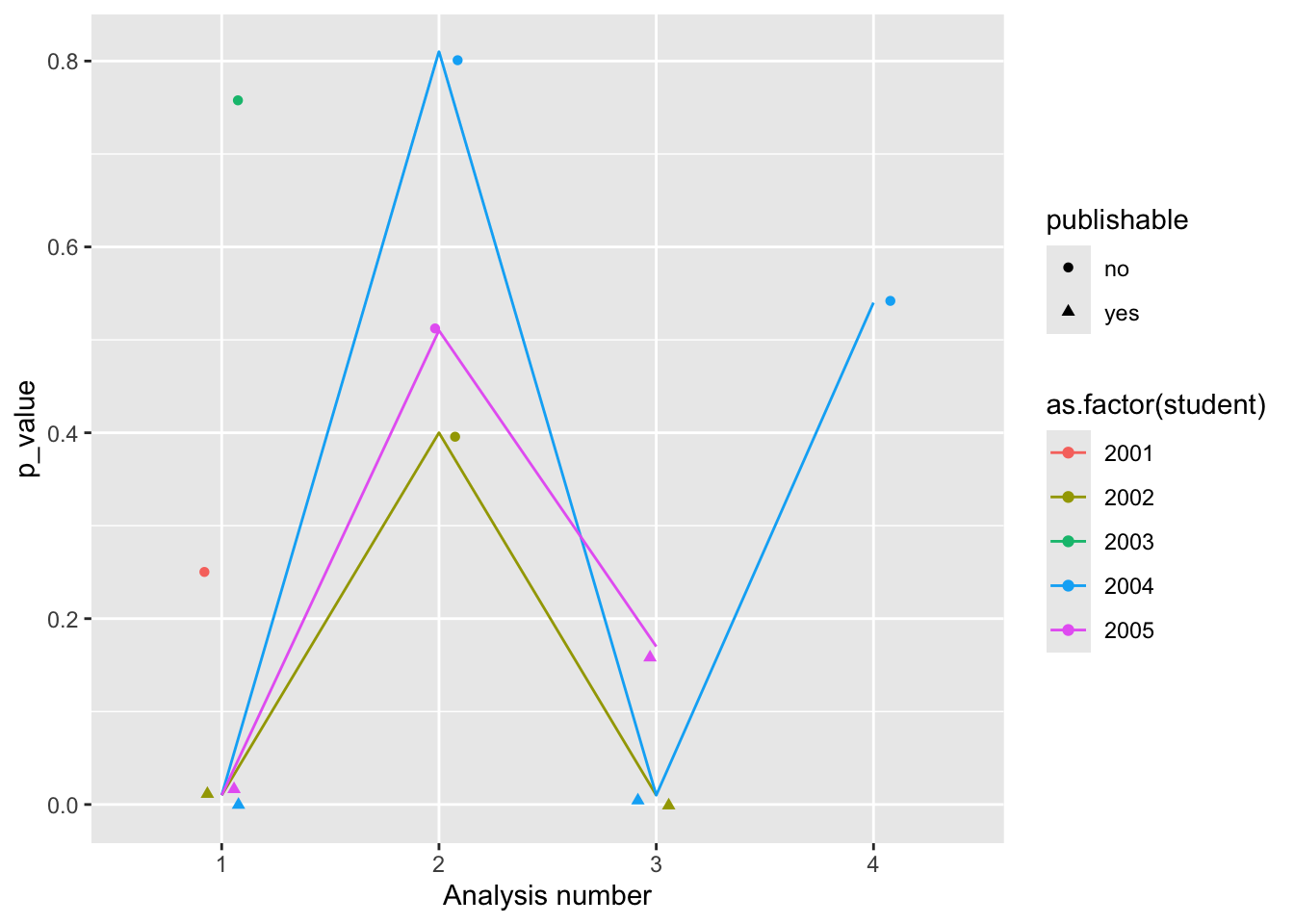
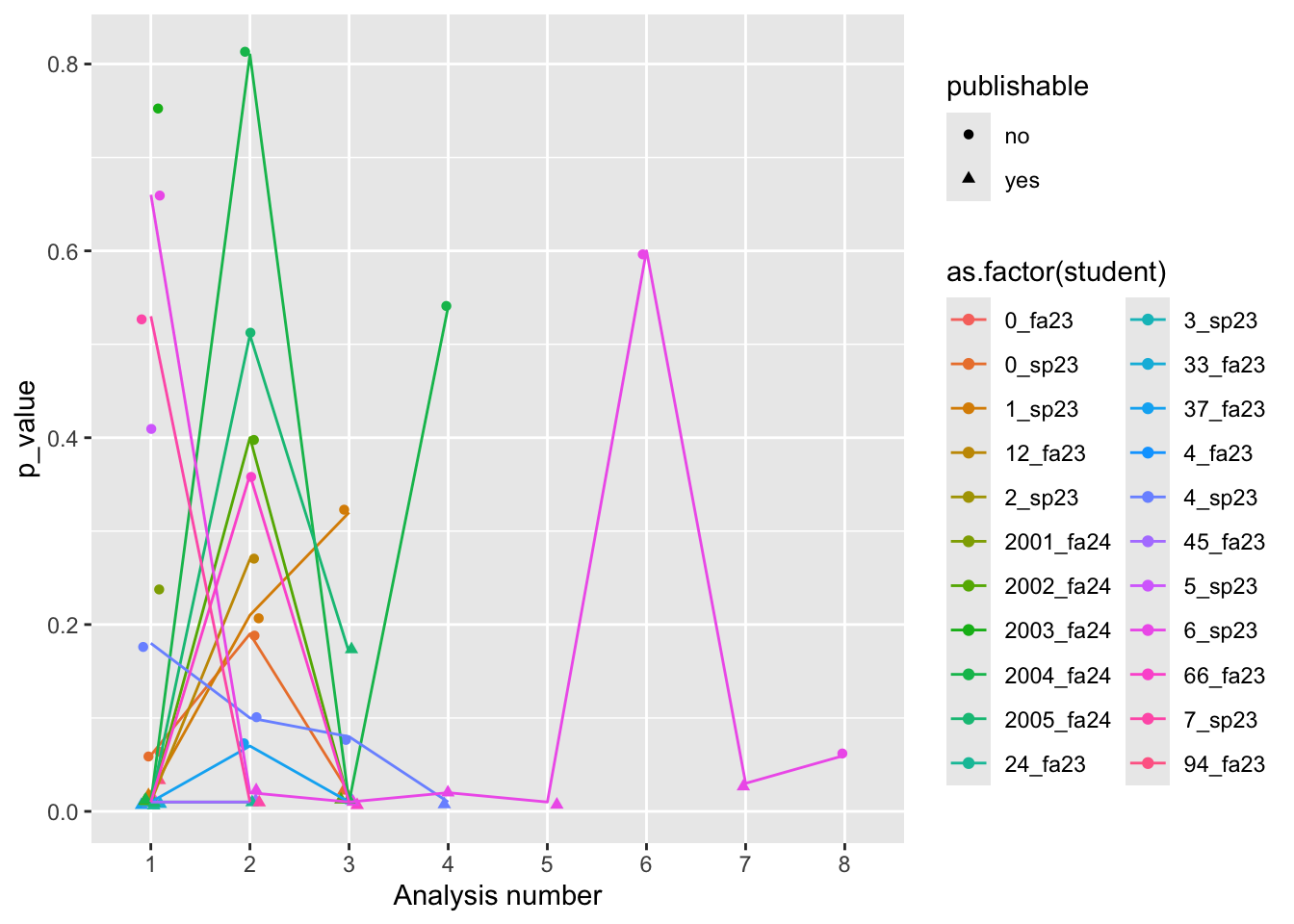
Figure 3: p-values by number of analyses: PSYCH 490 Fall 2024
How many different combinations of variables?
How many different combinations of variable choices are there?
There are \(n=4\) measures of political control; \(n=4\) measures of economic performance; \(n=2\) ‘other’ factors; \(n=2\) prediction choices; and \(n=2\) political parties to focus on.
We can use the combinat package to help us figure this out.
And there is only one way to pick 4 among 4. Make sense?
If we add these up ‘4 + 6 + 4 + 1’ = 15 we get the number of different choices we can make (15) about how many combinations of political power measures are possible.
Since there are also 4 different choices of economic performance measures, we know that there are 15 ways to pick these. Now we can calculate how many different possible combinations of variables there are.
n_combos <-15*15*2*2*2
We multiply because each of the choices (political power, economic performance, party, better or worse is independent).
So, there are \(n=\) 1800 of variables we could have chosen. How does this impact the conclusions we can and should draw?
Combine with Spring 2023 data?
We did the same exercise in Spring 2023 and Fall 2023. Let’s combine our data with theirs.
`summarise()` has grouped output by 'party', 'prediction'. You can override
using the `.groups` argument.
party
prediction
econ_measures
n_preds
democrats
better
employment
21
democrats
better
gdp
19
democrats
better
inflation
13
democrats
better
stocks
11
republicans
better
employment
11
republicans
better
inflation
11
republicans
better
stocks
9
republicans
better
gdp
7
republicans
worse
employment
7
republicans
worse
gdp
6
republicans
worse
inflation
6
democrats
worse
employment
4
democrats
worse
stocks
4
democrats
worse
gdp
0
democrats
worse
inflation
0
republicans
worse
stocks
0
Figure 5: Respondents’ choices of economic measures in their analyses
References
Wilkinson, M. D., Dumontier, M., Aalbersberg, I. J. J., Appleton, G., Axton, M., Baak, A., … Mons, B. (2016). The FAIR guiding principles for scientific data management and stewardship. Scientific Data, 3, 160018. https://doi.org/10.1038/sdata.2016.18