First, we load the external packages (groups of R commands) that we will be using.
Gathering
Next, we download the data from the Google Sheet where it is collected. Dr. Gilmore has stored his Google account credentials in a special environment file that can be accessed by the R command Sys.getenv("GMAIL_SURVEY").
Tip
It’s vital to be very careful when creating and sharing code like this that involves sensitive information like login credentials.
Gilmore likes to put credentials in an .Renviron file that lives in his home directory. This is a recommended practice. On Mac OS and Linux, that’s ~/.Renviron. You can use the usethis::edit_r_profile() command at the R console (not the Terminal) to open your own .Renviron file. In Gilmore’s case, he has added the following line to that file:
GMAIL_SURVEY="<my-google-account>"
Where he has substituted his Google account with credentials/access to the required files for <my-google-account>. Then, when the R code below calls `Sys.getenv(“GMAIL_SURVEY”), the value of those credentials is returned.
Make sure to close and save the .Renviron file and restart your R session before testing this yourself.
The data file has been saved as a comma-separated value (CSV) format data file in a special directory called csv/.
Note
Because these data might contain sensitive or identifiable information, we only keep a local copy and do not share it publicly via GitHub. This is achieved by adding the name of the data directory to a special .gitignore file.
We have n=15 responses as of 2024-12-12 11:20:36.341502. Note: Two of these are “test” responses by Dr. Gilmore.
Here are the column “names”:
Code
# Google Forms puts the full question in the top row of the data file.# We use the names() function to extract and print the original questions.survey_02_norms_qs <-names(survey_02_norms)survey_02_norms_qs
[1] "Timestamp"
[2] "Scientists are generally motivated by the desire for knowledge and discovery, and not by the possibility of personal gain....2"
[3] "Scientists make an attempt to consider all new evidence, hypotheses, theories, and innovations, even those that challenge or contradict their own work....3"
[4] "Scientists generally assess new knowledge and its applications based on the reputation and past productivity of the individual or research group....4"
[5] "Scientists openly share new findings with all colleagues....5"
[6] "Scientists generally invest their careers in promoting their own most important findings, theories, or innovations....6"
[7] "Scientists compete with others in the same field for funding and recognition of their achievements....7"
[8] "Scientists generally evaluate research only on its merit (i.e., according to accepted standards of the field)....8"
[9] "Scientists emphasize the protection of their newest findings to ensure priority in publishing, patenting, or applications....9"
[10] "Scientists are generally motivated by the desire for knowledge and discovery, and not by the possibility of personal gain....10"
[11] "Scientists make an attempt to consider all new evidence, hypotheses, theories, and innovations, even those that challenge or contradict their own work....11"
[12] "Scientists generally assess new knowledge and its applications based on the reputation and past productivity of the individual or research group....12"
[13] "Scientists openly share new findings with all colleagues....13"
[14] "Scientists generally invest their careers in promoting their own most important findings, theories, or innovations....14"
[15] "Scientists compete with others in the same field for funding and recognition of their achievements....15"
[16] "Scientists generally evaluate research only on its merit (i.e., according to accepted standards of the field)....16"
[17] "Scientists emphasize the protection of their newest findings to ensure priority in publishing, patenting, or applications....17"
[18] "If you wish to comment about the questions in this survey, you may do so here. You are not required to comment. However, if you want extra credit points for completing the survey, put a code phrase here and tell the TA what it is."
We see that these are the full text of the questions asked.
Clean/shorten names
For plotting and analyses, it’s usually easier to shorten the questions by creating a short name that reflects the underlying idea or construct. We’ll use the rename() function from the dplyr package for this.
Code
new_names <-c("timestamp","Disinterestedness_should","Organized Skepticism_should","Particularism_should","Communality_should","Organized Dogmatism_should","Self-interestedness_should","Universalism_should","Solitariness_should","Disinterestedness_actually","Organized Skepticism_actually","Particularism_actually","Communality_actually","Organized Dogmatism_actually","Self-interestedness_actually","Universalism_actually","Solitariness_actually","comments" )# These data are ‘wide’, meaning that there are multiple variables for each respondent. The data will be easier to visualize and analyze if we make the data ‘longer’.# Swap out old (long) names for new (short) nameslong_names <-names(survey_02_norms)names(survey_02_norms) <- new_names
Assign a unique code to each respondent’s responses:
Code
# Use stringr::str_pad() to 'pad' numbers so that all of them are 2 characters# wide.survey_02_norms <- survey_02_norms |> dplyr::mutate(sub_id =paste0("s_", stringr::str_pad(seq_along(comments), width =2,pad =0)))
Create a “longer” table with each row representing a single question rating from a single respondent.
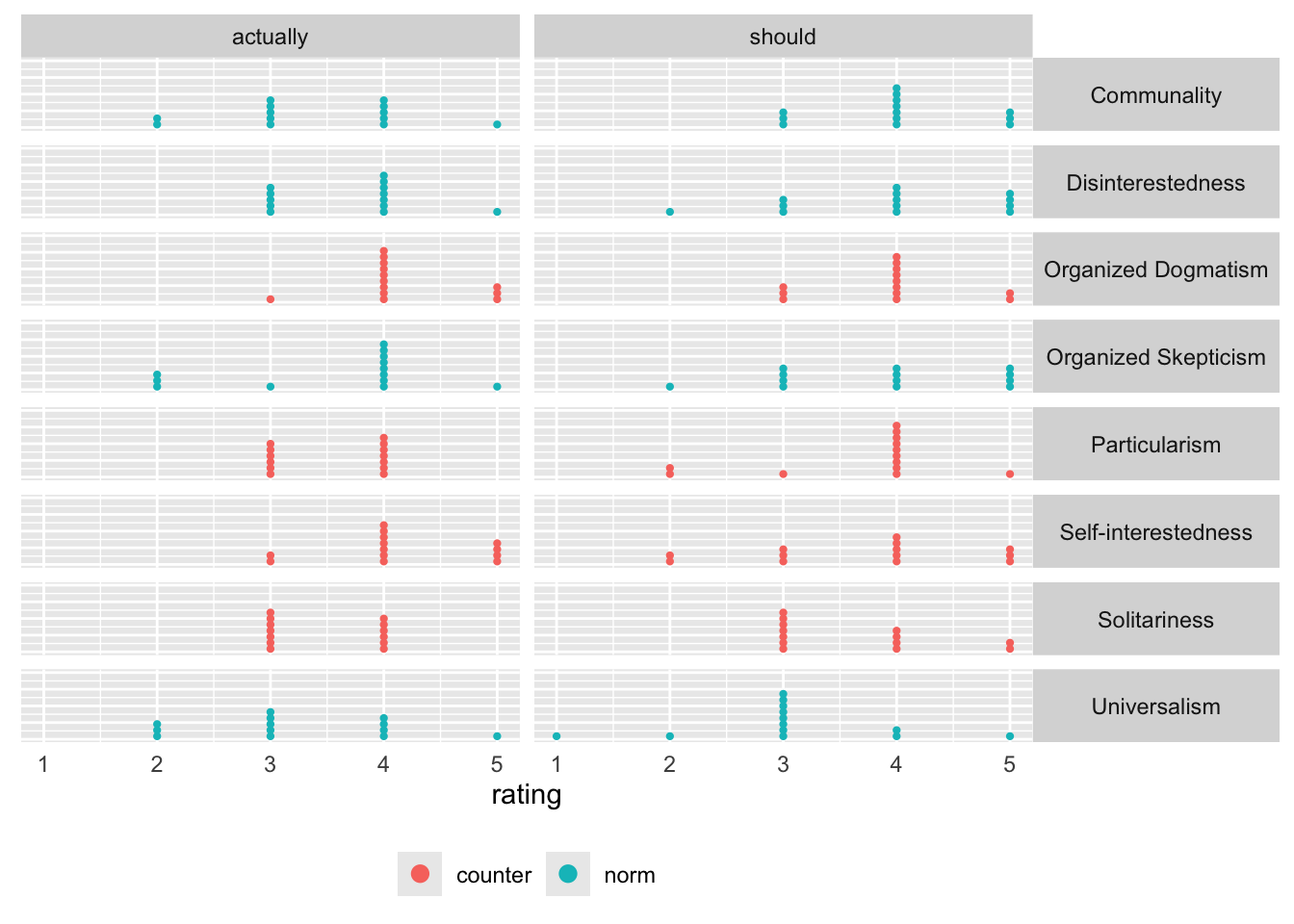
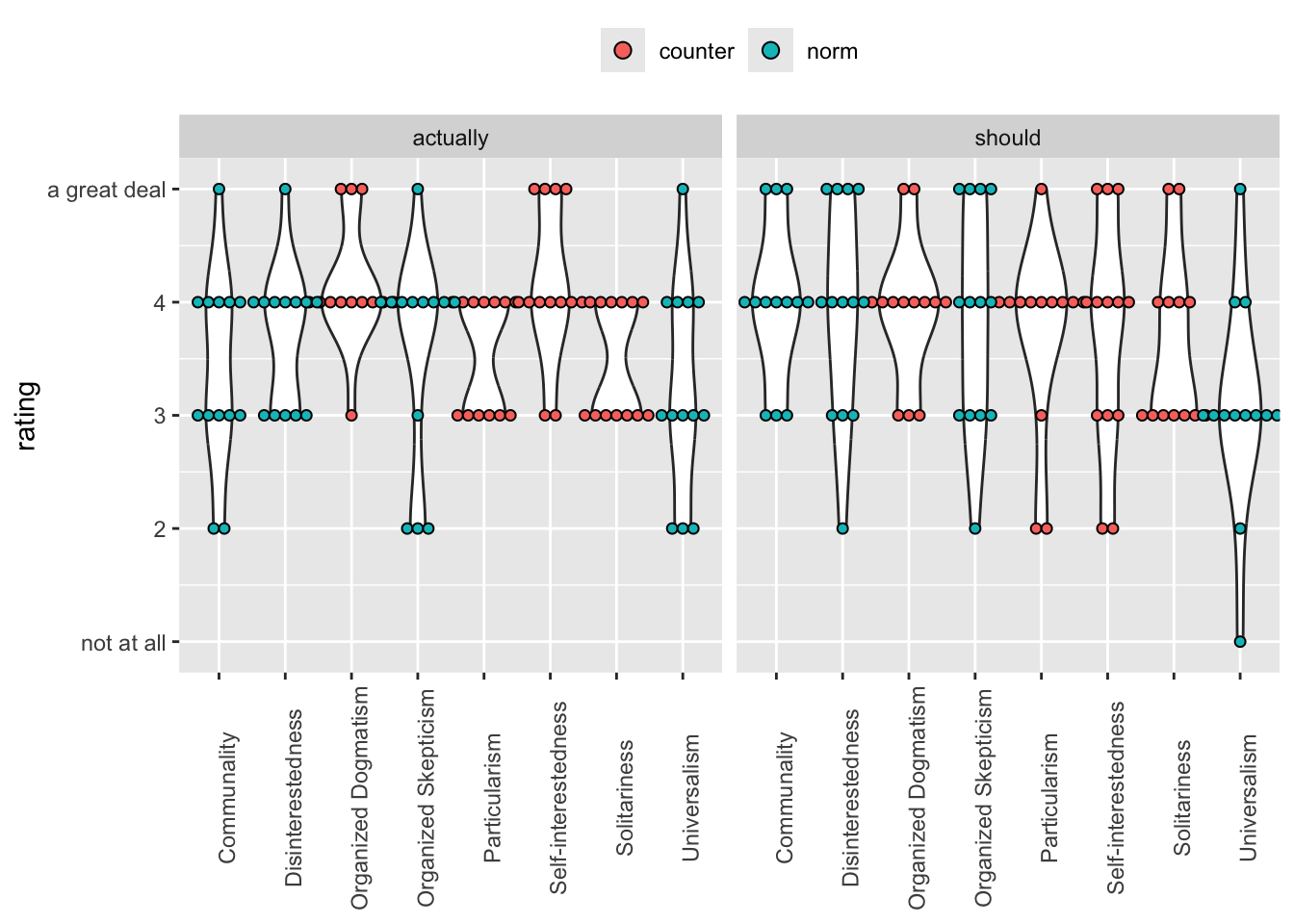
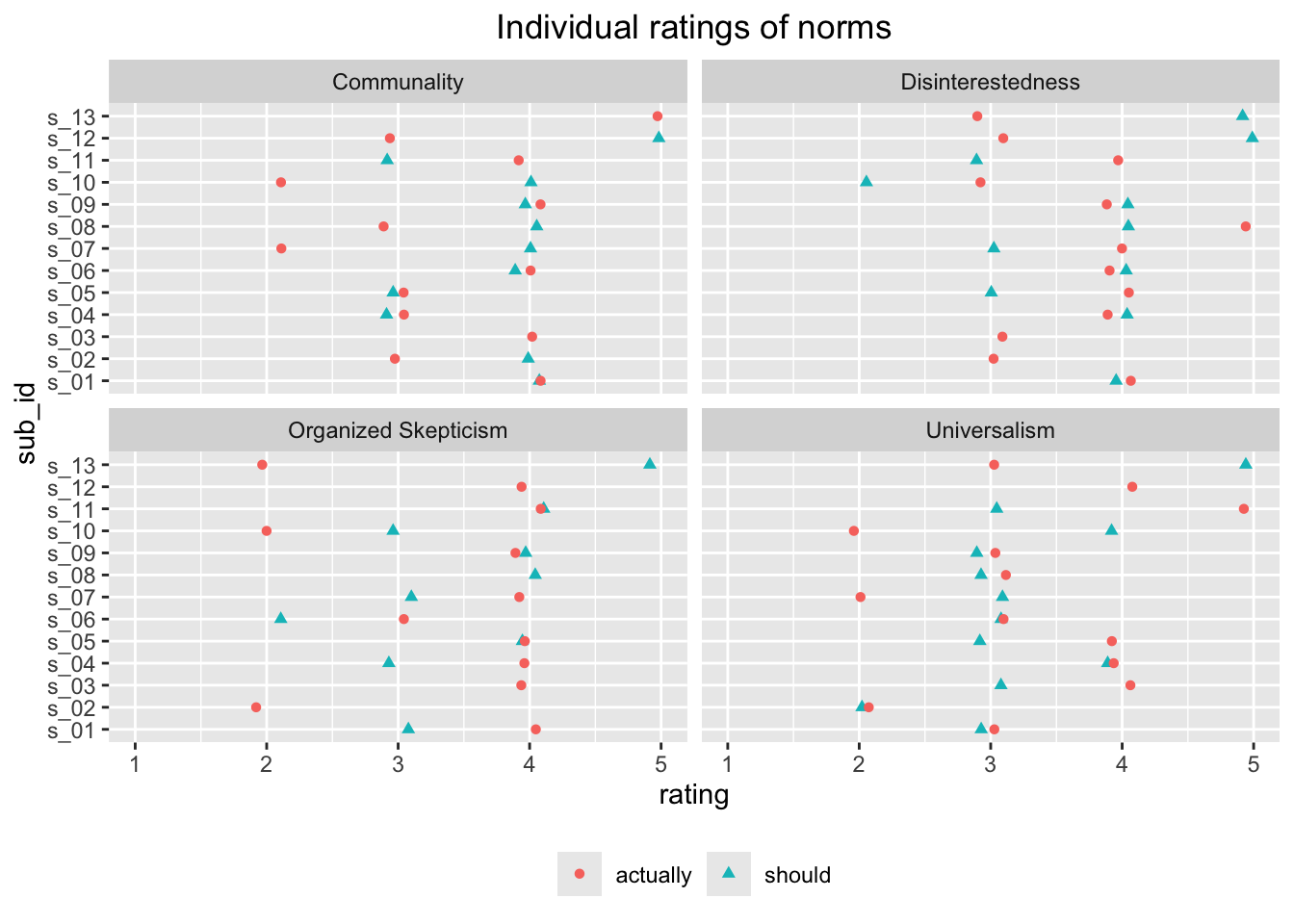
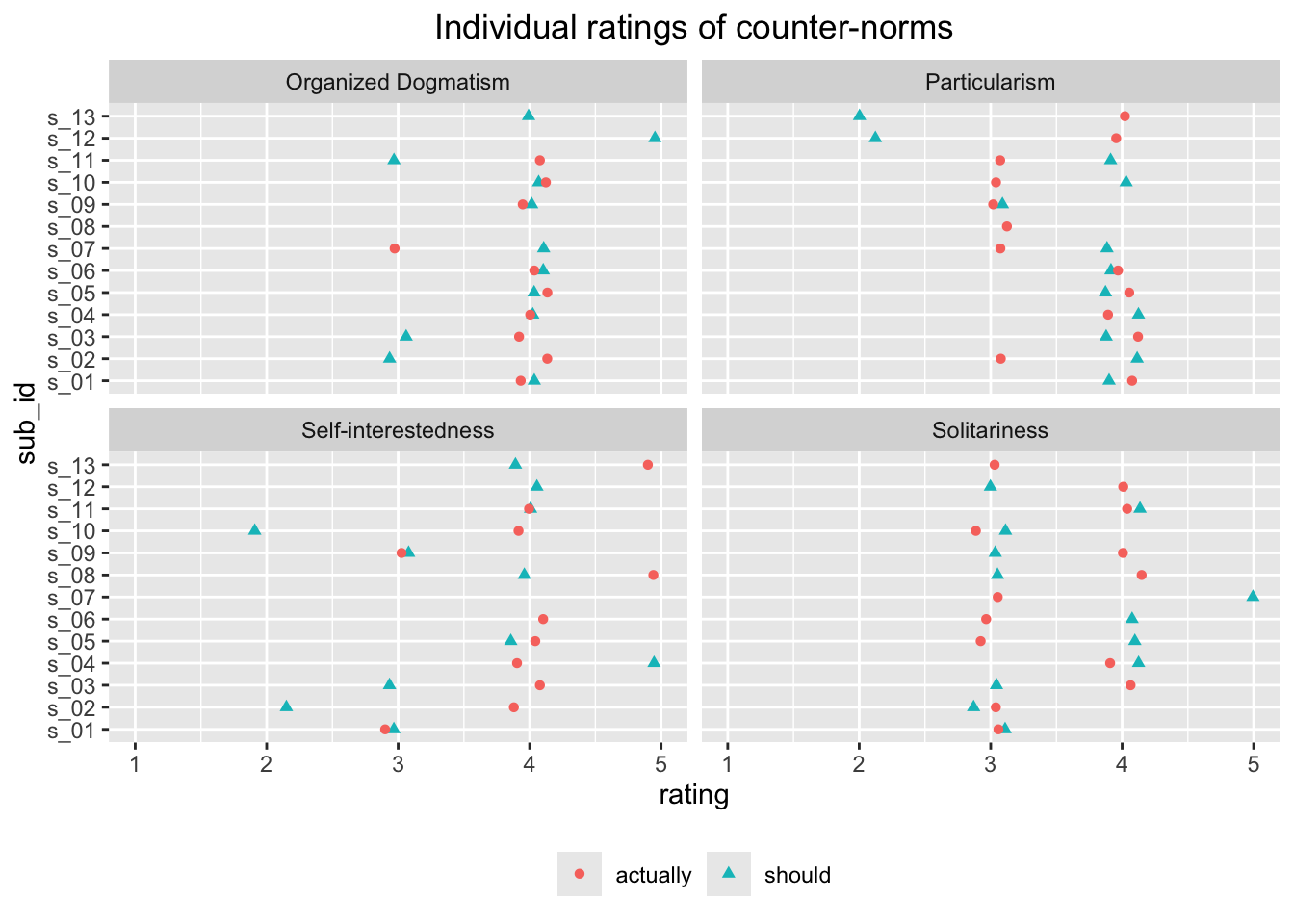
We move the ’_should’ and ’_actually’ from the question to a separate variable called ‘resp_frame’ for response frame. Then we create a variable that indicates whether the statements are norms or counternorms.
Code
survey_02_norms_long <- survey_02_norms_long |> dplyr::mutate(resp_frame = stringr::str_extract(norm_counternorm, "should|actually")) |> dplyr::mutate(norm_counternorm = stringr::str_remove_all(norm_counternorm, "_[a-z]+"))# We should indicate whether these are norms or counternorms.survey_02_norms_long <- survey_02_norms_long |> dplyr::mutate(type =if_else( norm_counternorm %in%c("Disinterestedness","Organized Skepticism","Communality","Universalism" ),"norm",# Changed to shorter 'counter' on 2024-09-16"counter" ))
Now, let’s look at the names to confirm that they all got changed.
We’ll pause here to start building a data dictionary, a file that explains the origin, format, and usage of our dataset.
Code
# Make new data frame with long and short names for referencesurvey_02_norms_data_dictionary <- tibble::tibble(q_long = long_names, q_short = new_names)survey_02_norms_data_dictionary <- survey_02_norms_data_dictionary |> dplyr::mutate(norm_type =if_else( stringr::str_detect( q_short,"Disinterestedness|Skepticism|Communality|Universalism"),"norm","counter" )) |> dplyr::mutate(resp_frame =if_else( stringr::str_detect( q_short,"should"),"should_do","actually_do" ))# The `norm_type` and `resp_frame` variables have no meaning for the timestamp or comments.survey_02_norms_data_dictionary$norm_type[1] <-NAsurvey_02_norms_data_dictionary$norm_type[18] <-NAsurvey_02_norms_data_dictionary$resp_frame [1] <-NAsurvey_02_norms_data_dictionary$resp_frame [18] <-NA
We’ll add other items to the data dictionary later.
Visualizations
Code
n_responses <-dim(survey_02_norms)[1] # number of rows in originalif (n_responses <1) {message("Insufficient responses to plot.")} else { survey_02_norms |> dplyr::mutate(resp_index =1:n_responses) |> dplyr::mutate(timestamp = lubridate::mdy_hms(timestamp)) |>ggplot() +aes(x = timestamp, resp_index) +geom_point() +geom_line() +ggtitle("Time series of responses to Survey-02") +scale_y_continuous(breaks =1:12) +theme(axis.text.x =element_text(angle =90),axis.title.x =element_blank(),plot.title =element_text(hjust =0.5) )}
Kardash, C. M., & Edwards, O. V. (2012). Thinking and behaving like scientists: Perceptions of undergraduate science interns and their faculty mentors. Instructional Science, 40(6), 875–899. https://doi.org/10.1007/s11251-011-9195-0