Remember, the simulation allows us to do something we can’t do in real life: Determine in advance the size of some effect we want to measure using an experiment. Doing this is useful because we can see what can happen if the world is exactly the way we think it is. The world is rarely if ever this way, but having this kind of control is a great check on our assumptions.
Here, we want to simulate a small effect size to see what a meta-analysis might yield in a situation where there is really an effect, but it’s small.
Enter data for the Sample size, Mean difference between A and B, the low and high values for your confidence interval (CI), and a study identifier you choose. I just used ‘gilmore-01’ for my first simulation.
Change the sample size to another value (not the default n=75). Report your data and change your study identifier.
Either keep the same sample size and hit the ‘regenerate’ button or change the sample size. When you change the sample size, the simulation will automatically regenerate new data. Report those data in the Google Form.
Set-up
We load the packages we will use.
library('ggplot2')library('dplyr')
Attaching package: 'dplyr'
The following objects are masked from 'package:stats':
filter, lag
The following objects are masked from 'package:base':
intersect, setdiff, setequal, union
Warning: Removed 3 rows containing missing values or values outside the scale range
(`geom_segment()`).
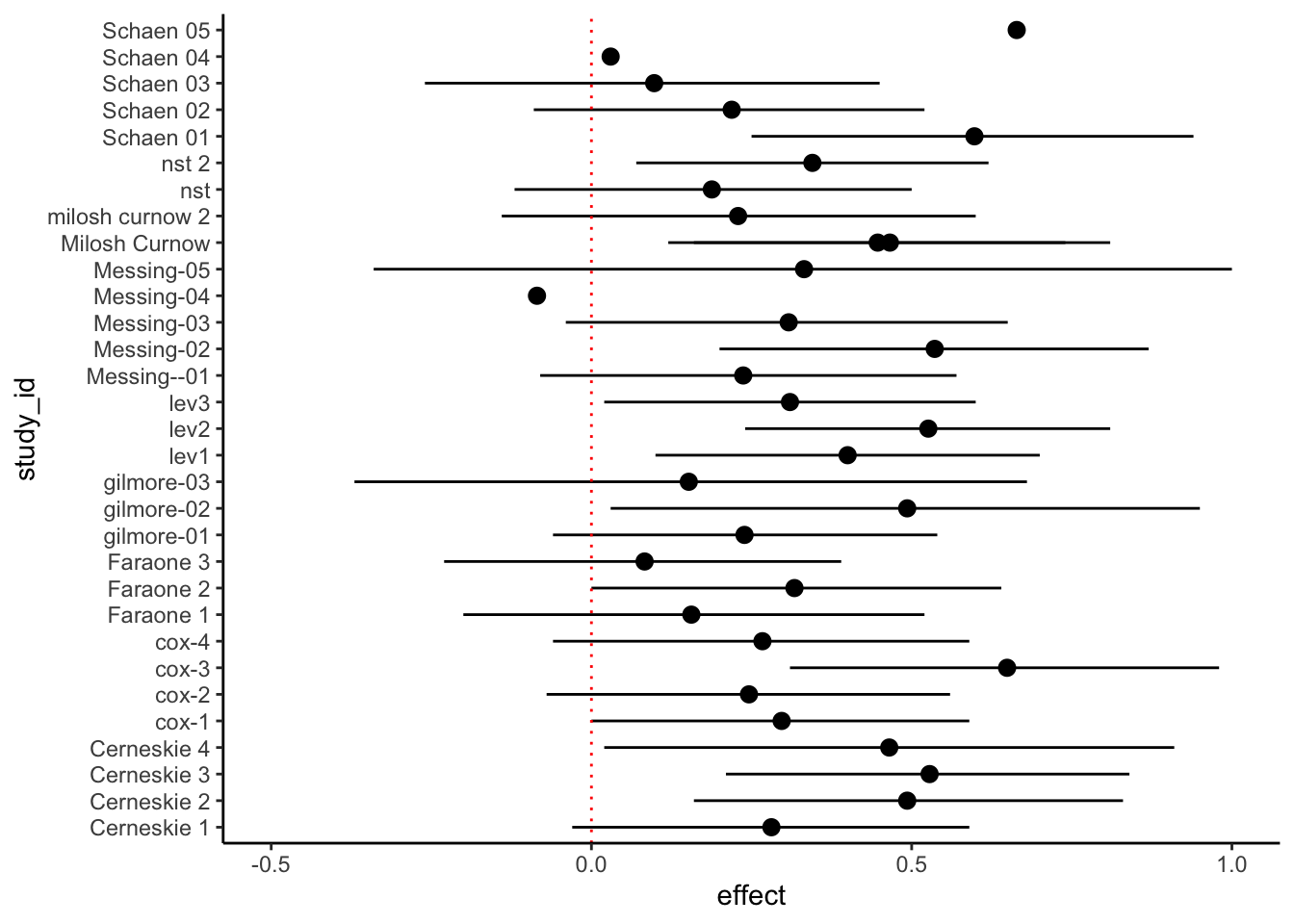
Figure 1: Simulating a meta-analysis of an experiment with d=0.3. The size of the dots is proportional to the sample size (n).
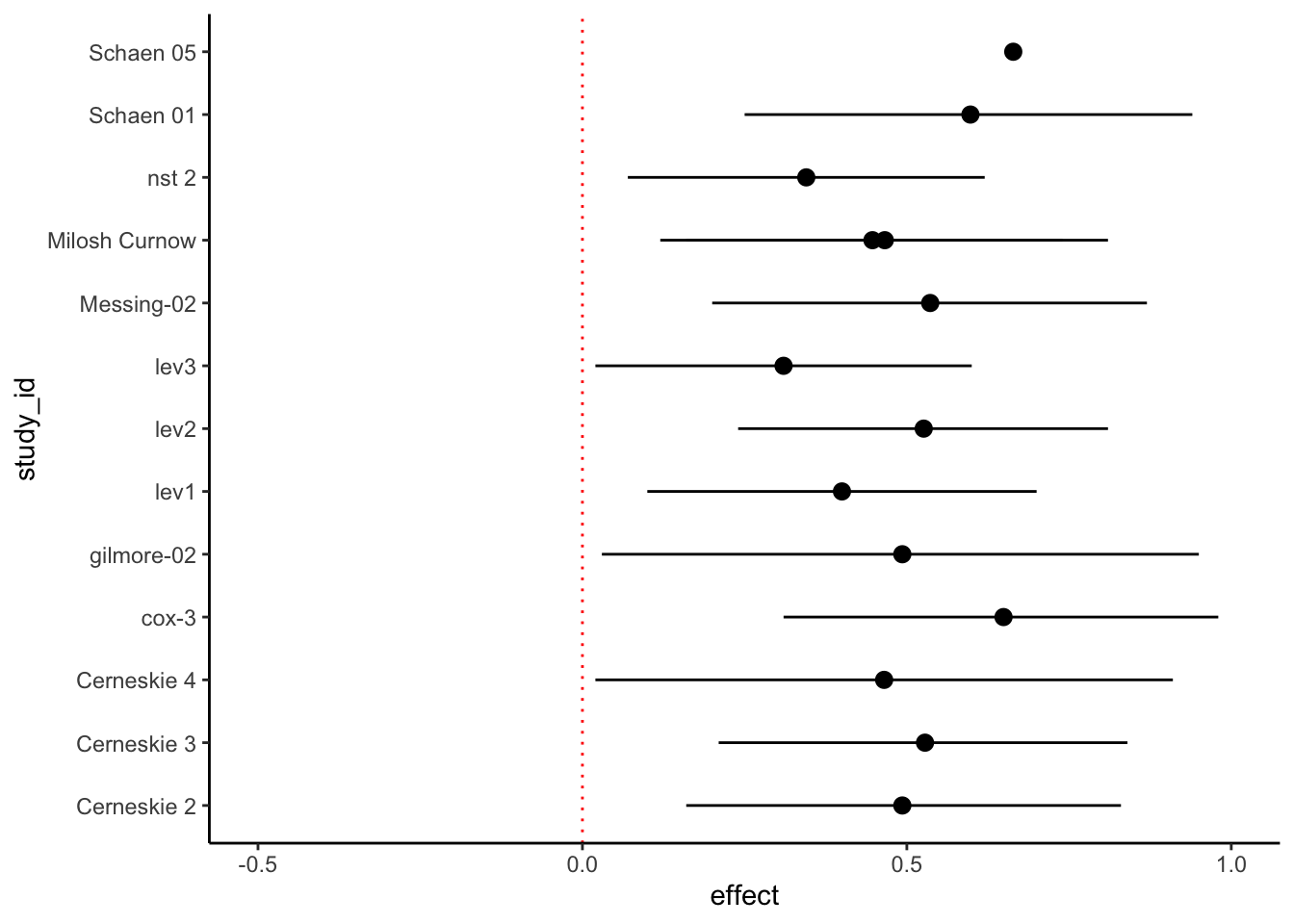
Can we simulate what this would look like if there was a big file drawer effect?
Let’s eliminate all of the examples where the CI included zero.
meta_analysis |># filter (remove) all entries where `ci_low` is less than zero. dplyr::filter(ci_low >0) |> dplyr::arrange(desc(effect)) |>ggplot() +aes(x = effect, y = study_id) +geom_point() +geom_pointrange(aes(x = effect, xmin=ci_low, xmax=ci_high)) +xlim(-.5, 1) +theme_classic() +theme(legend.position ="none") +geom_vline(xintercept =0, linetype ="dotted", color ="red")
Warning: Removed 1 row containing missing values or values outside the scale range
(`geom_segment()`).
Figure 2: Simulating a meta-analysis of an experiment with d=0.3. The size of the dots is proportional to the sample size (n). We remove studies whose CI’s include 0.