This section describes some ways to generate plots using the R package ggplot2.
Why R
R is a programming language specialized for data analysis and visualization.
Background
ggplot2 is a package1 for making 2D plots in R. It implements a special “language” for making plots based on the grammar of graphics suggested by Wilkinson, Wills, Rope, Norton, & Dubbs (2005). That’s where the ‘gg’ in the name comes from.
In ggplot, we create a base plot, then add layers to it using a plus sign + operator.
Set-up
To check whether ggplot2 is already installed, run the following chunk:
Code
# The require() function returns TRUE if ggplot2 is installed and FALSE if it is not. The exclamation point symbol ('!') turns FALSE into TRUE and TRUE into FALSE. So, `!require(ggplot2)` will be TRUE if require(ggplot2) is FALSE. When this occurs, the `install.packages(ggplot)` commands runs and installs ggplot2.if (!require(ggplot2)) {install.packages(ggplot2)}
Loading required package: ggplot2
Plotting one variable
Discrete/nominal
First, we make some data. We store two variables, category and value using the data.frame() command. A data frame is a convenient, spreadsheet-like structure for storing data.
Here we create a data frame and give it the name data_random_discrete. You can choose any name you want, subject to R’s restrictions on naming things. I try to use descriptive names.
The data frame name suggests that we have a random, continuous variable (value) and a discrete or categorical variable (category). The data frame command stores the variable names along with the data. We can see this by using R’s names() command:
Sometimes it’s useful to look at the structure of something using the str() command.
Code
str(data_random_discrete)
'data.frame': 8 obs. of 2 variables:
$ category: chr "ab" "xy" "mn" "qp" ...
$ value : num 4.8 5.5 3.5 4.6 6.5 6.6 2.6 3
Now that we have some data, let’s plot it.
Barplot
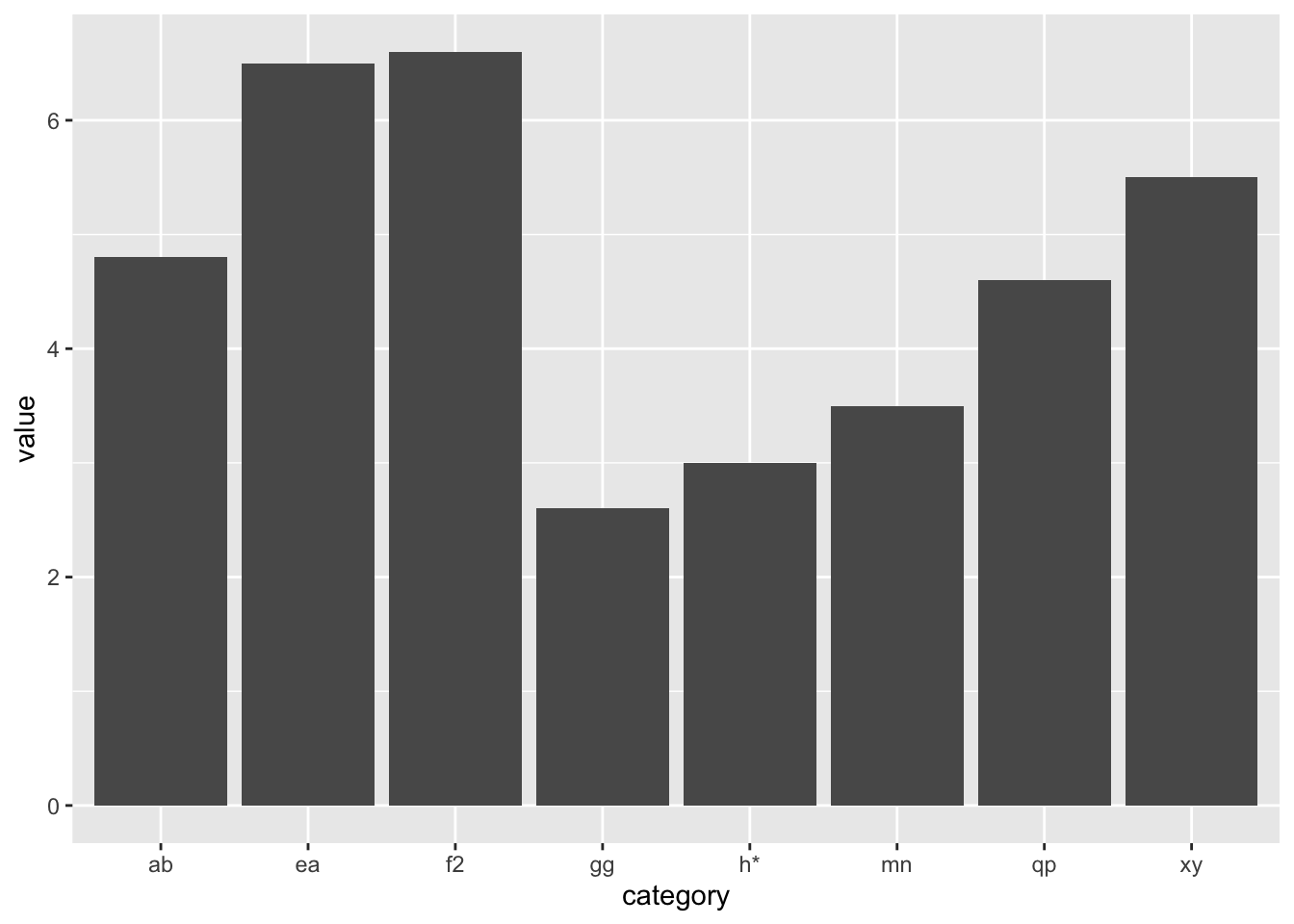
The following code makes a barplot. I’ll explain what’s going on after we look at the plot.
Code
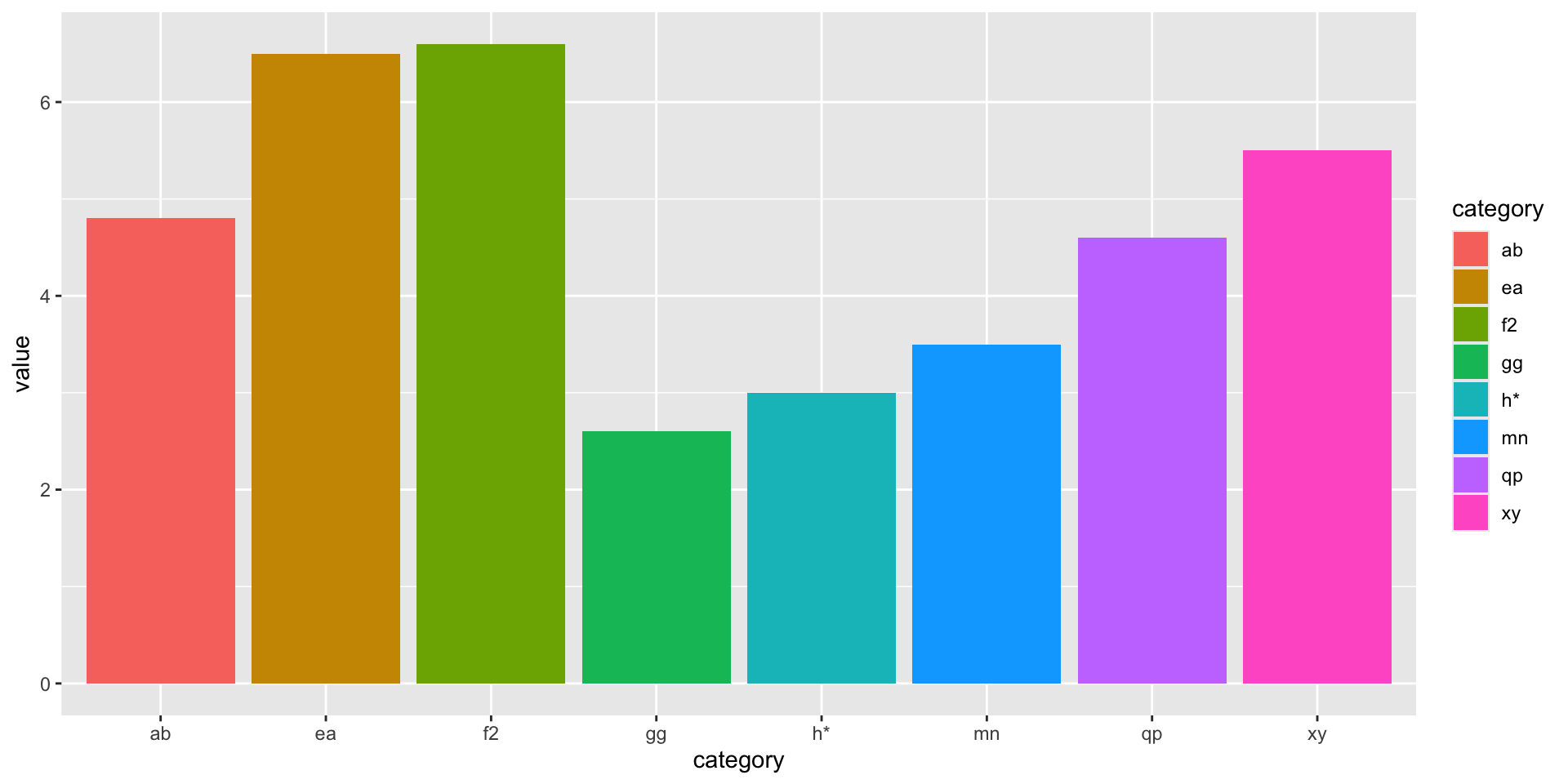
data_random_discrete |>ggplot() +aes(x = category, y = value) +geom_col()
Figure 1: A bar plot of our random data.
This code sends the data frame (data_random_discrete) to the ggplot() function using R’s pipe (|>) command.
Many ways to say the same thing
Like most (all?) programming languages, or really all languages, there are many ways to say the same thing.
I like using the pipe |> command because it makes the code a little easier for people to read.
The ggplot() function needs to know what data to plot, so this code
data_random_discrete |>ggplot()
tells ggplot(), “Hey, ggplot, create a plot with data from data_random_discrete.” An equivalent way to say the same thing is to assign data_random_discrete to ggplot’s data parameter, like this:
ggplot(data = data_random_discrete)
In fact, R turns the code above that uses the pipe into this format.
Now, running ggplot() alone like this doesn’t actually create a plot we can see. We have to tell ggplot() what variables to plot and what kind of plot to create. In the graphics grammar ggplot() understands we add information to the plot using the plus + character.
We tell ggplot() which variables to use by using the aesthetics aes() command.
ggplot() +aes(x = category, y = value)
Then, we add a graphic object or ‘geom’ to the plot.
aes(x = category, y = value) +
geom_col()
There are different types of geoms for different types of plots. You can think of each geom as a way to map data to graphic elements.
If the variable we want to plot contains the values we care about plotting, then we use geom_col. A column plot is just a type of barplot.
Here, we have a categorical variable imaginatively named category and a continuous variable named value.
See how the plot maps our category variable to the X axis and the value variable to the Y axis?
That’s the essence of making plots using ggplot(). We give ggplot() a data frame. Tell it which variables to assign to which aesthetics (properties of the plot). Add one or more geoms to make something we can see.
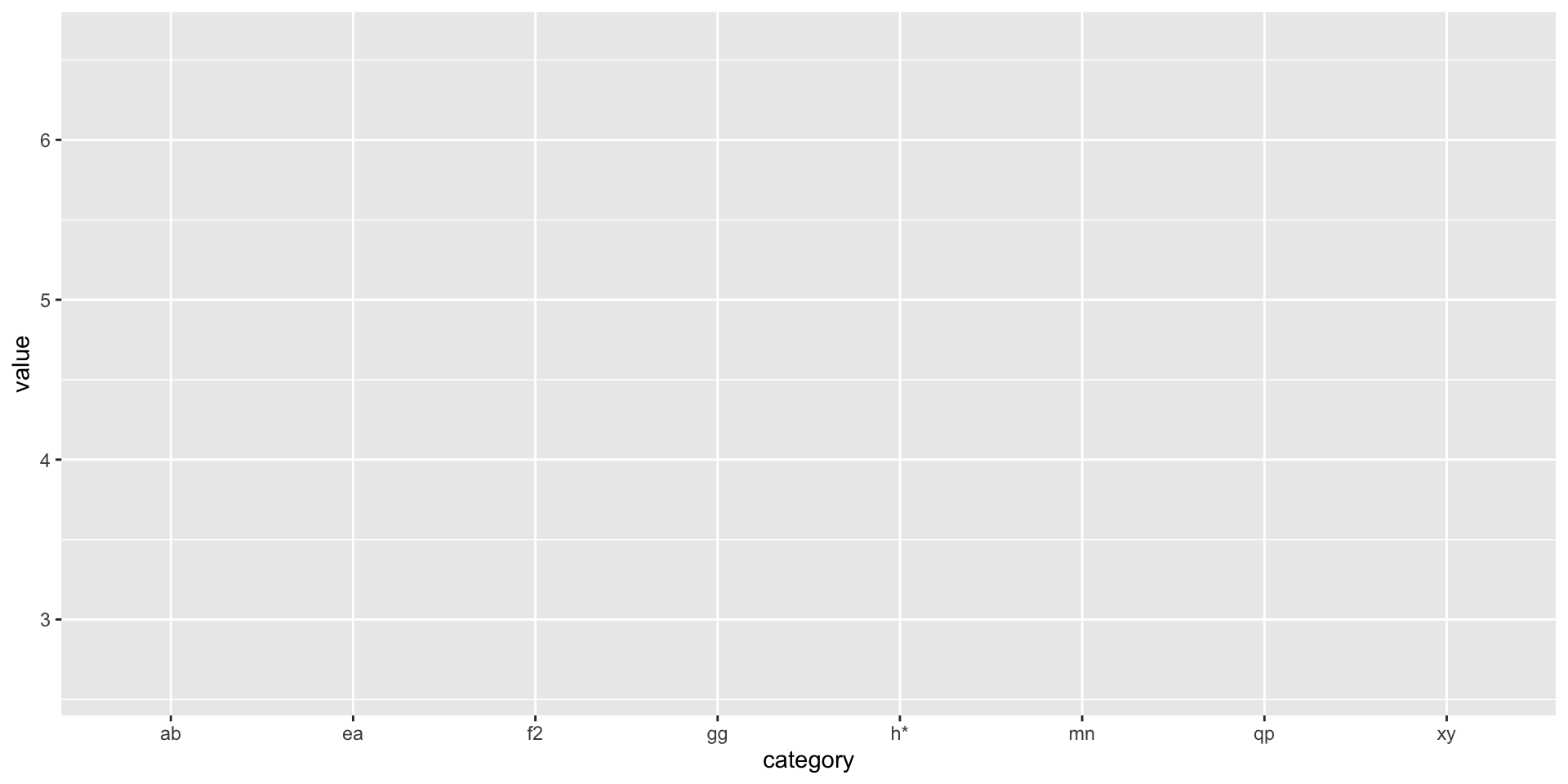
To break this down even further, the following code shows a way to make a plot step-by-step. This can be useful when you’re trying to figure out how you want to plot something.
Make a ggplot with data_random_discrete as the data.frame; give it the name p.
2
Show p.
Code
p <-ggplot(data = data_random_discrete)p
Figure 2: A ‘bare bones’ plot with data, but no aesthetics or graphics.
Notice that the plot is blank.
The blank plot isn’t very useful, so we have to add information to it about what variables we want to map to which aesthetic properties of the plot. The following code shows how this is done.
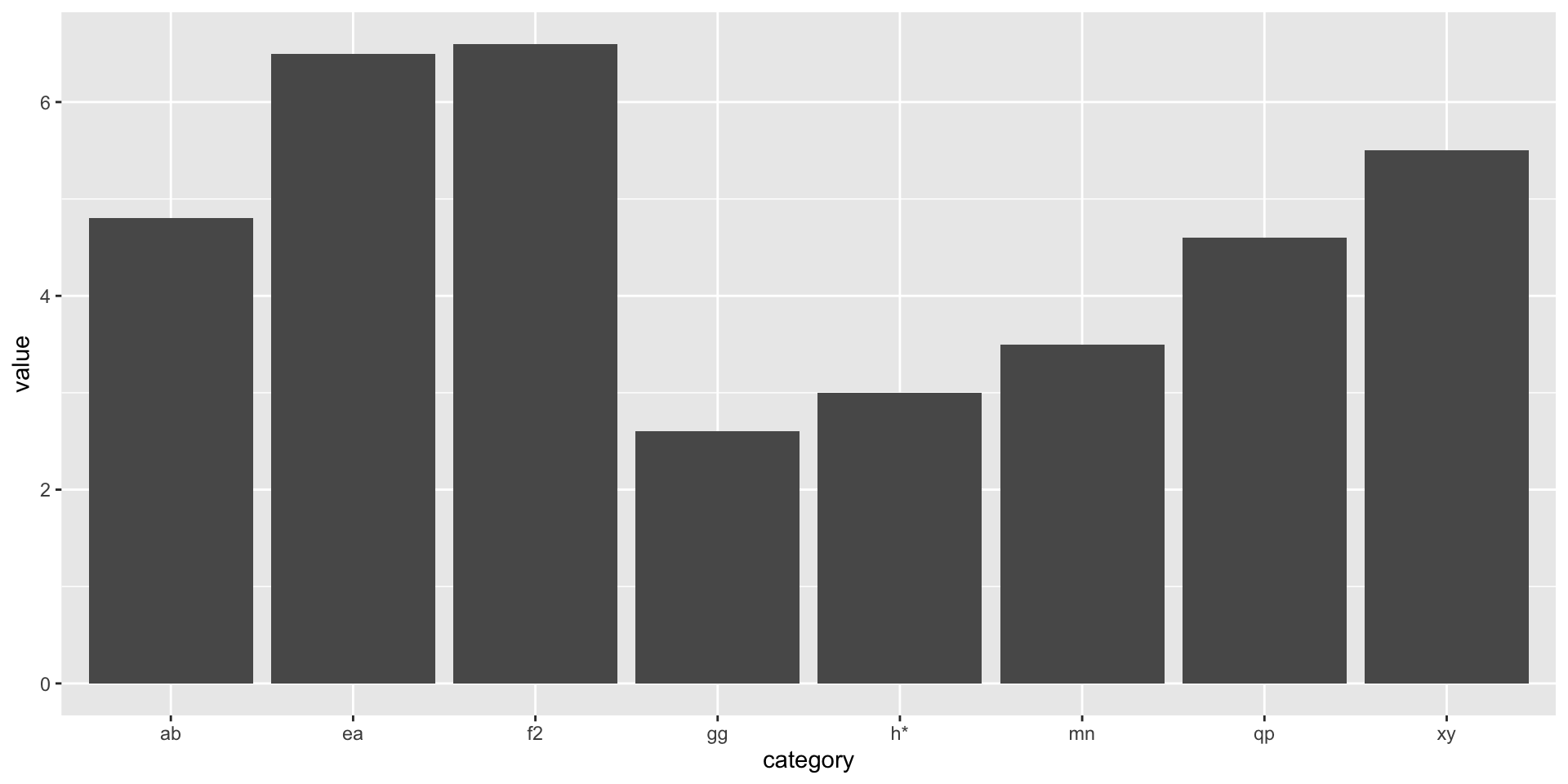
Add to p_aes a geom called geom_col(), a column or bar plot. Assign the combination to a new variable called p_col.
2
Show p_col.
Code
p_col <- p_aes +geom_col()p_col
Figure 4: A complete plot with data, aesthetics, and a geom
That looks good.
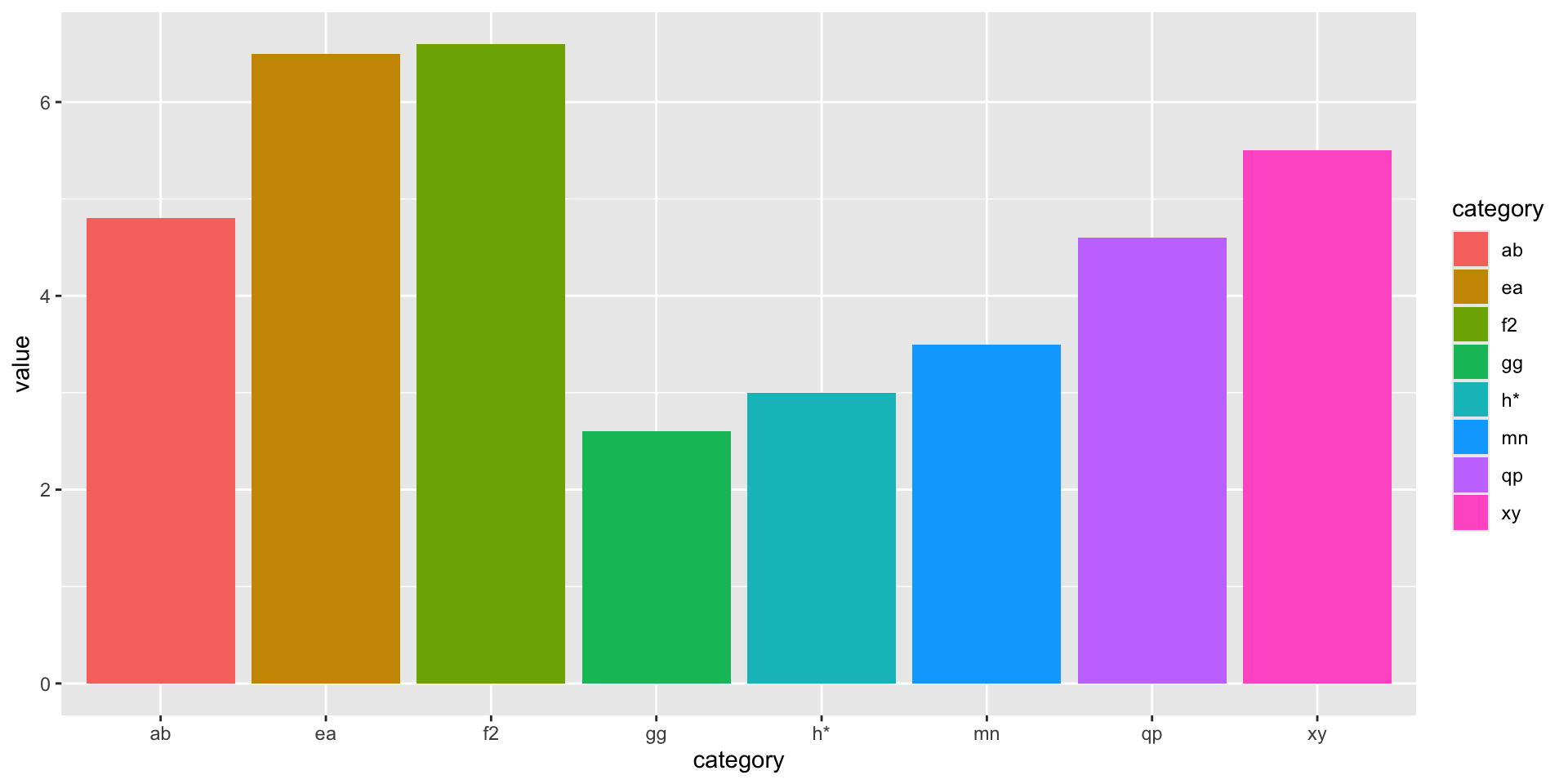
Let’s add some color to the bars. We do this by mapping the category variable to the fill property.
Code
p_colors <- p_col +aes(fill = category)p_colors
Figure 5: Adding an aesthetic based on ‘category’ to fill the bars with color.
We can wrap all of this up in a nice little sequence of code as follows:
Code
data_random_discrete |>ggplot() +aes(x = category, y = value, fill = category) +geom_col()
Figure 6: The same figure generated from a short sequence of commands.
Note that the category variables on the horizontal axis print in alphabetical order. Sometimes that might be what we want. But, what if we want to follow best practice and sort the bars in numeric order?
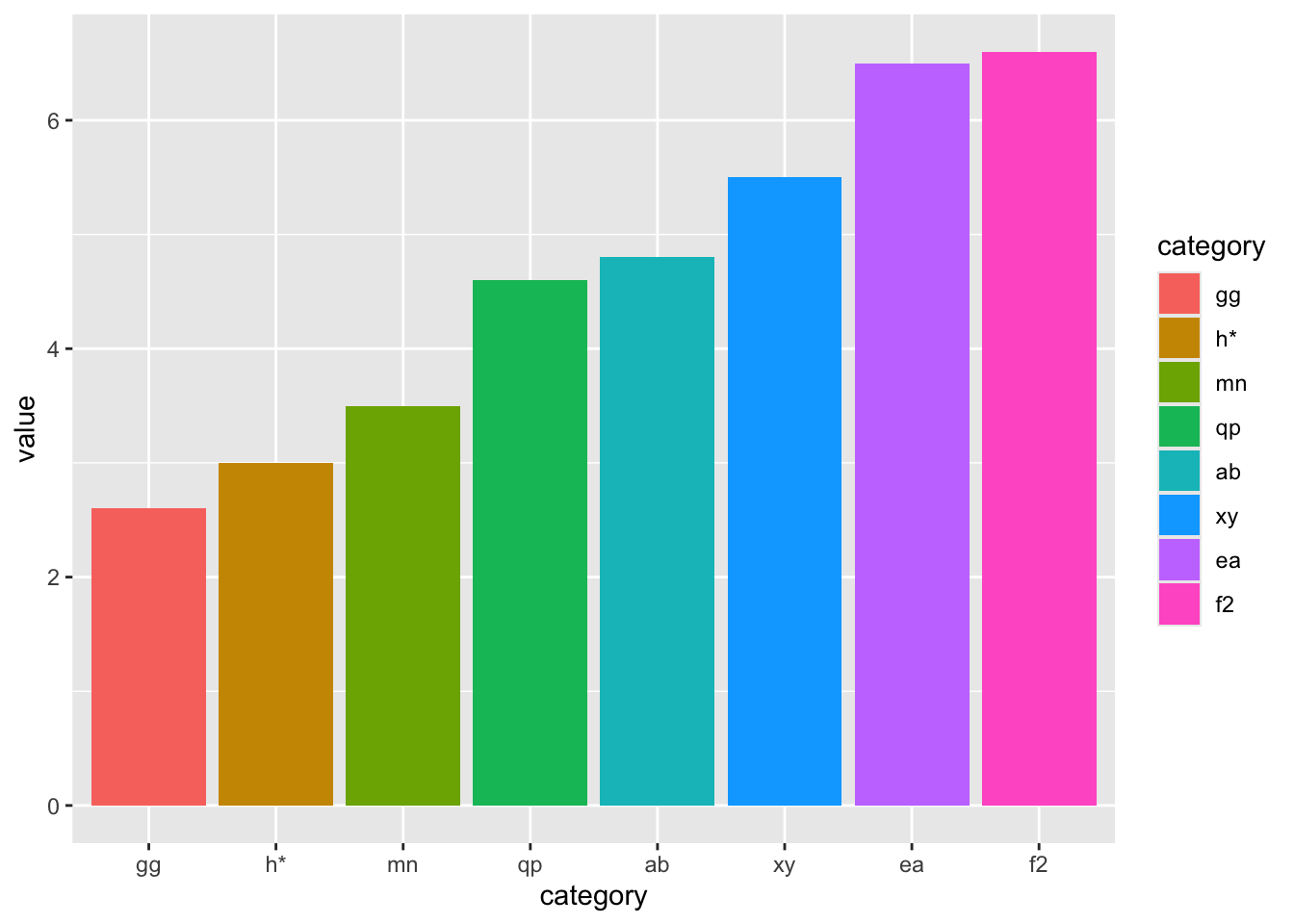
There are several ways to to this (see https://r-graph-gallery.com/267-reorder-a-variable-in-ggplot2.html), but the way shown below uses the forcats package to ‘mutate’ or change the ‘category’ variable into one that is reordered by the ‘value’ variable. Note that the default is to sort in ascending order.
Code
library(forcats)library(dplyr)
Attaching package: 'dplyr'
The following objects are masked from 'package:stats':
filter, lag
The following objects are masked from 'package:base':
intersect, setdiff, setequal, union
Code
data_random_discrete |>mutate(category =fct_reorder(category, value)) |>ggplot() +aes(x = category, y = value, fill = category) +geom_col()
Figure 7: The same plot but with the columns ordered by ‘value’.
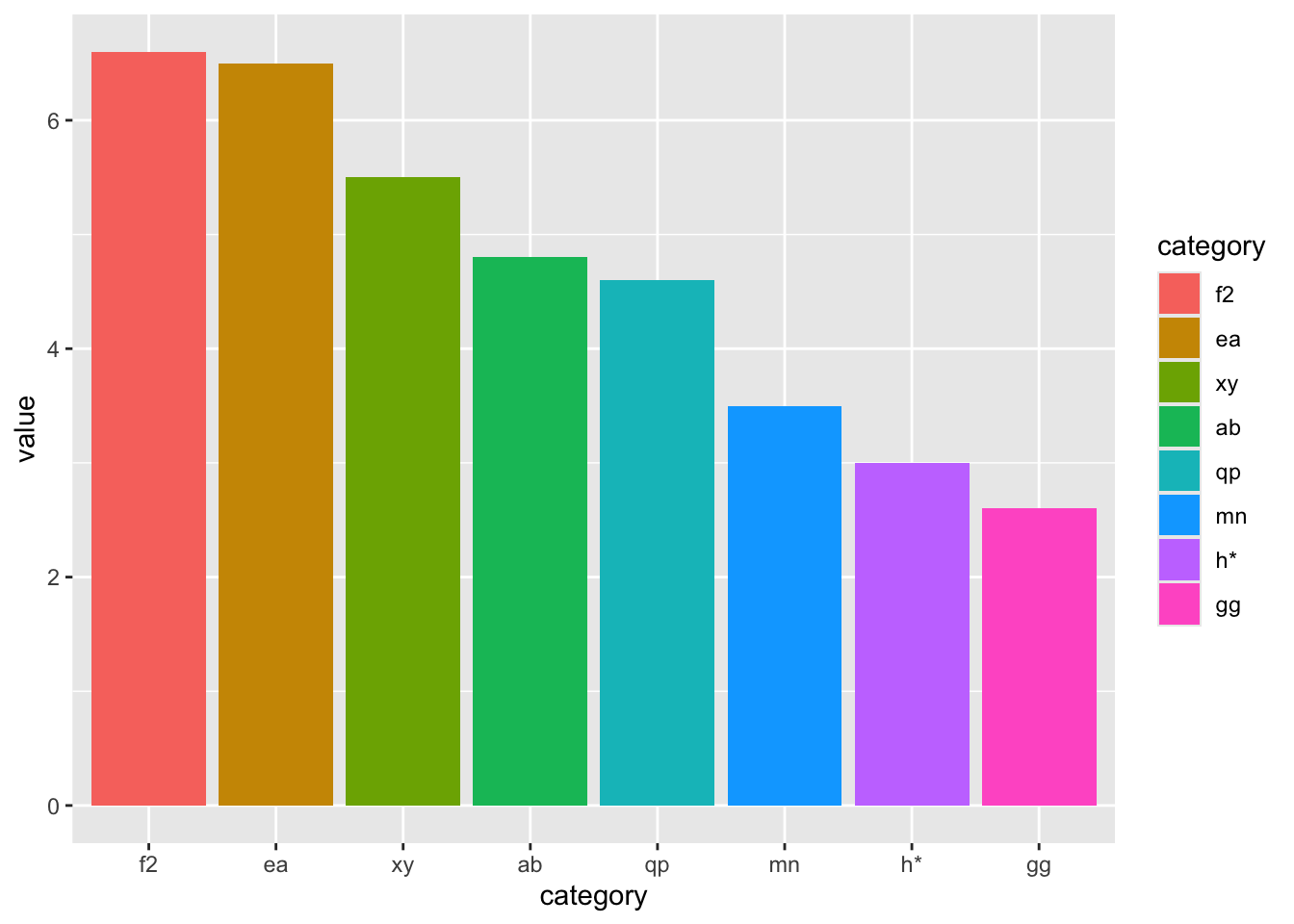
To reverse the order from ascending to descending, the default, we use the desc() function to sort value from highest to lowest value, as in the following:
Code
data_random_discrete |>mutate(category =fct_reorder(category, desc(value))) |>ggplot() +aes(x = category, y = value, fill = category) +geom_col()
Figure 8: The same plot but with the columns ordered by ‘value’ in descending order.
Your turn
What would we need to do to make the category variable ordinal?
Why do we think that value is continuous?
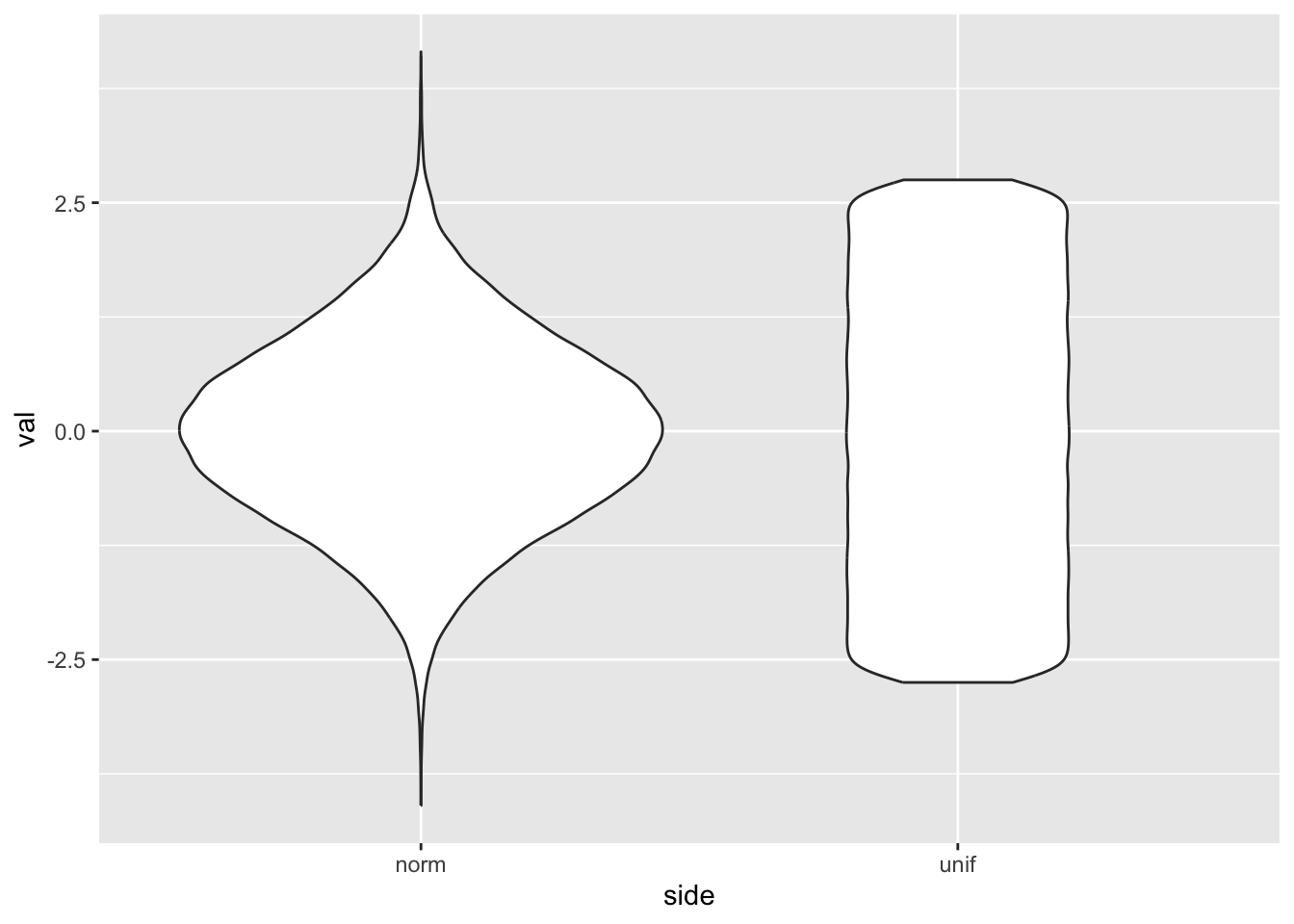
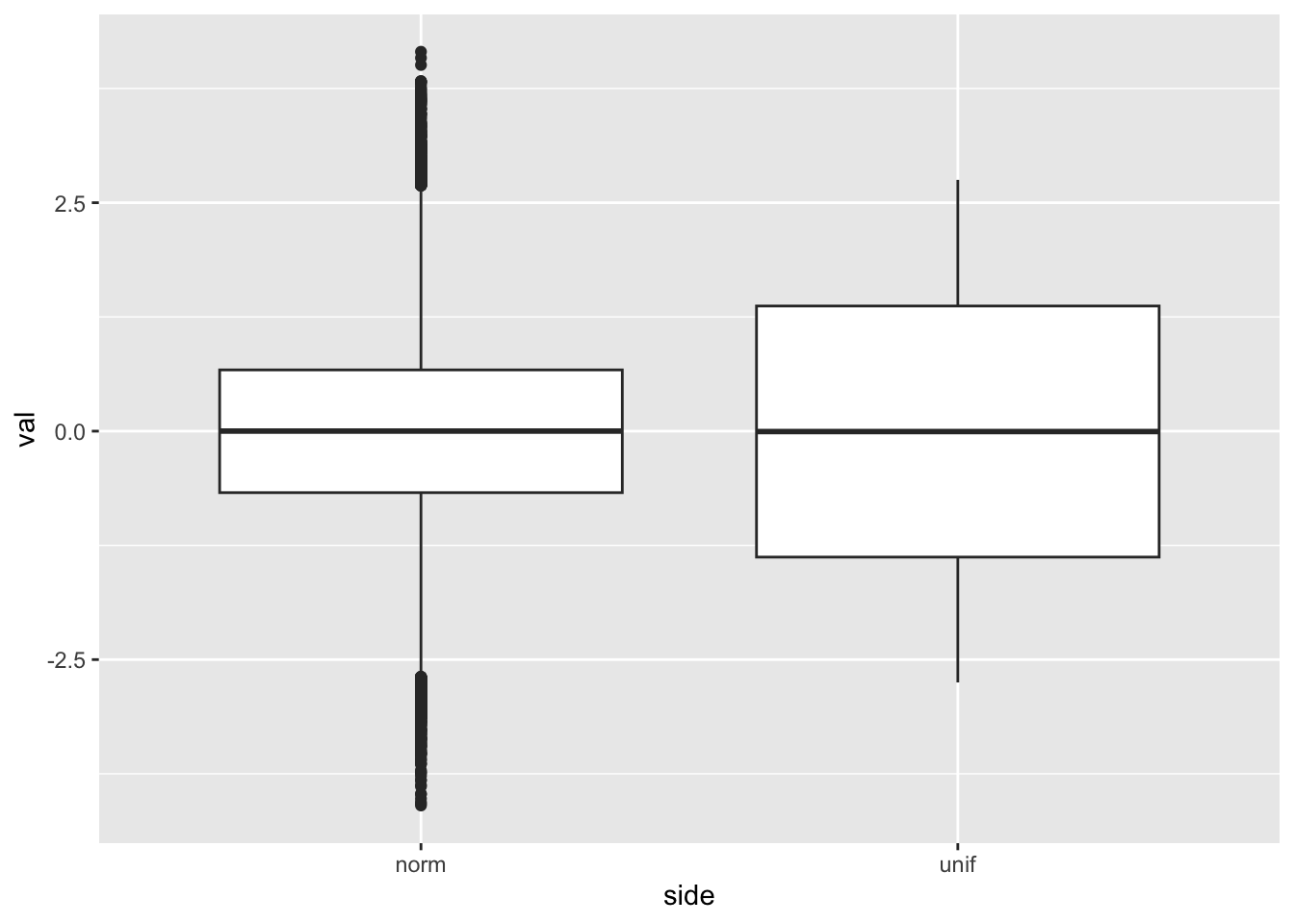
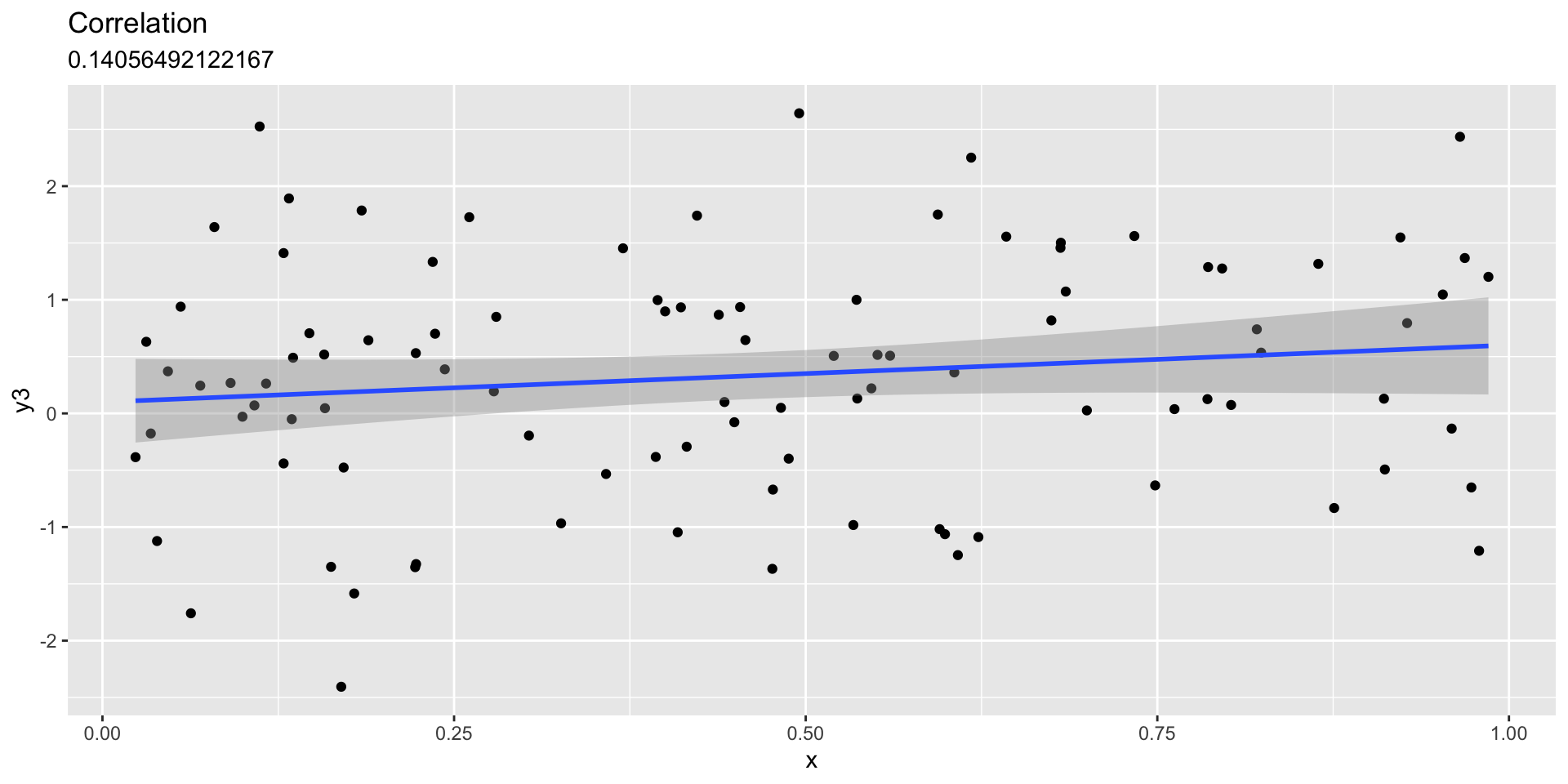
Continuous
First, let’s generate some random data.
Code
# Set a seed for our 'random' number generatorset.seed(19680801)n_values <-100000data_random_norm <-data.frame(val =rnorm(n = n_values, mean =0, sd =1))
What the code is saying is this: Send data_random_norm to ggplot; make the plot and its various layers; then give the plot a name (hist_1) so we can use it later. Like now, for instance:
Code
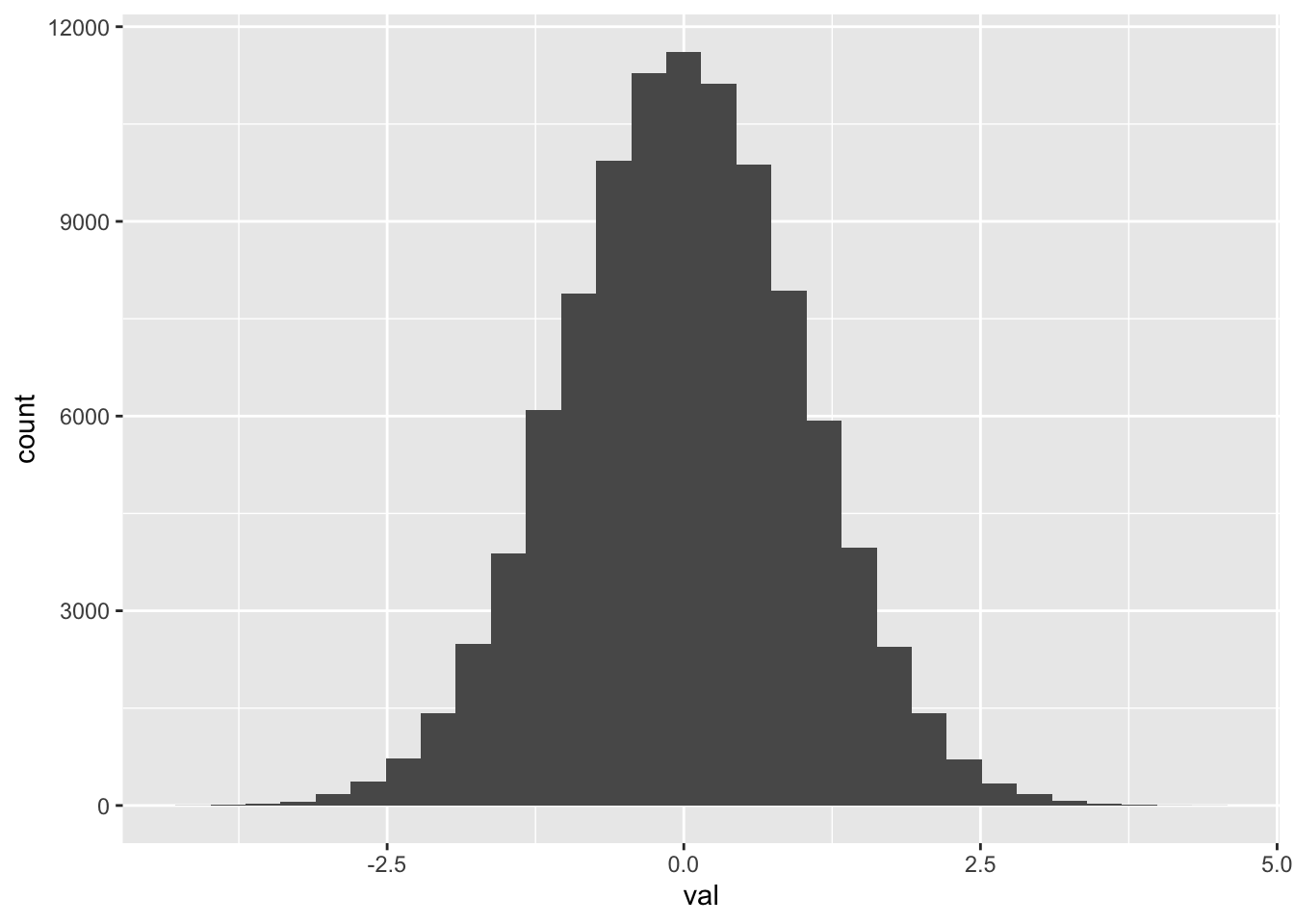
hist_1
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
Figure 9: A simple histogram
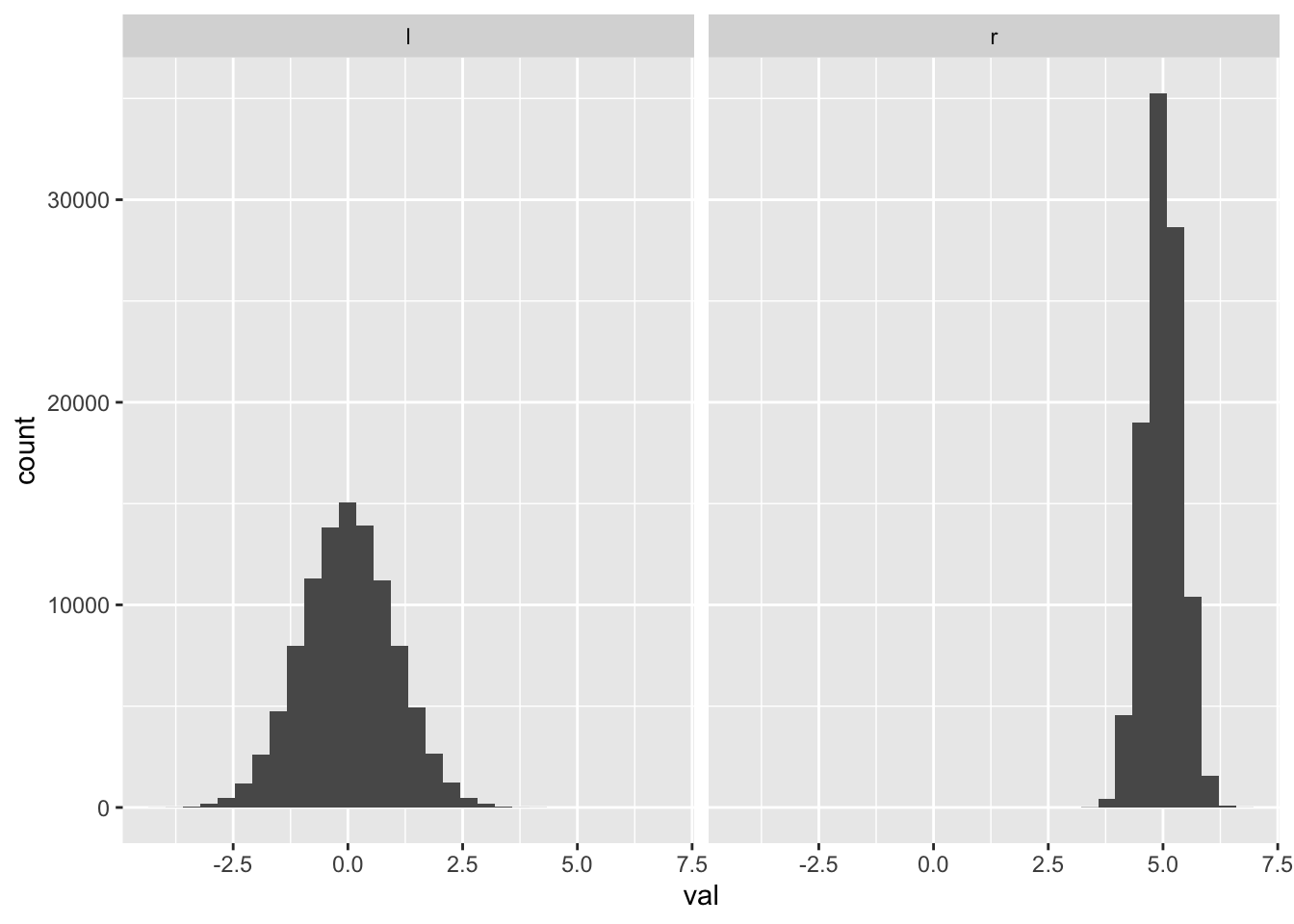
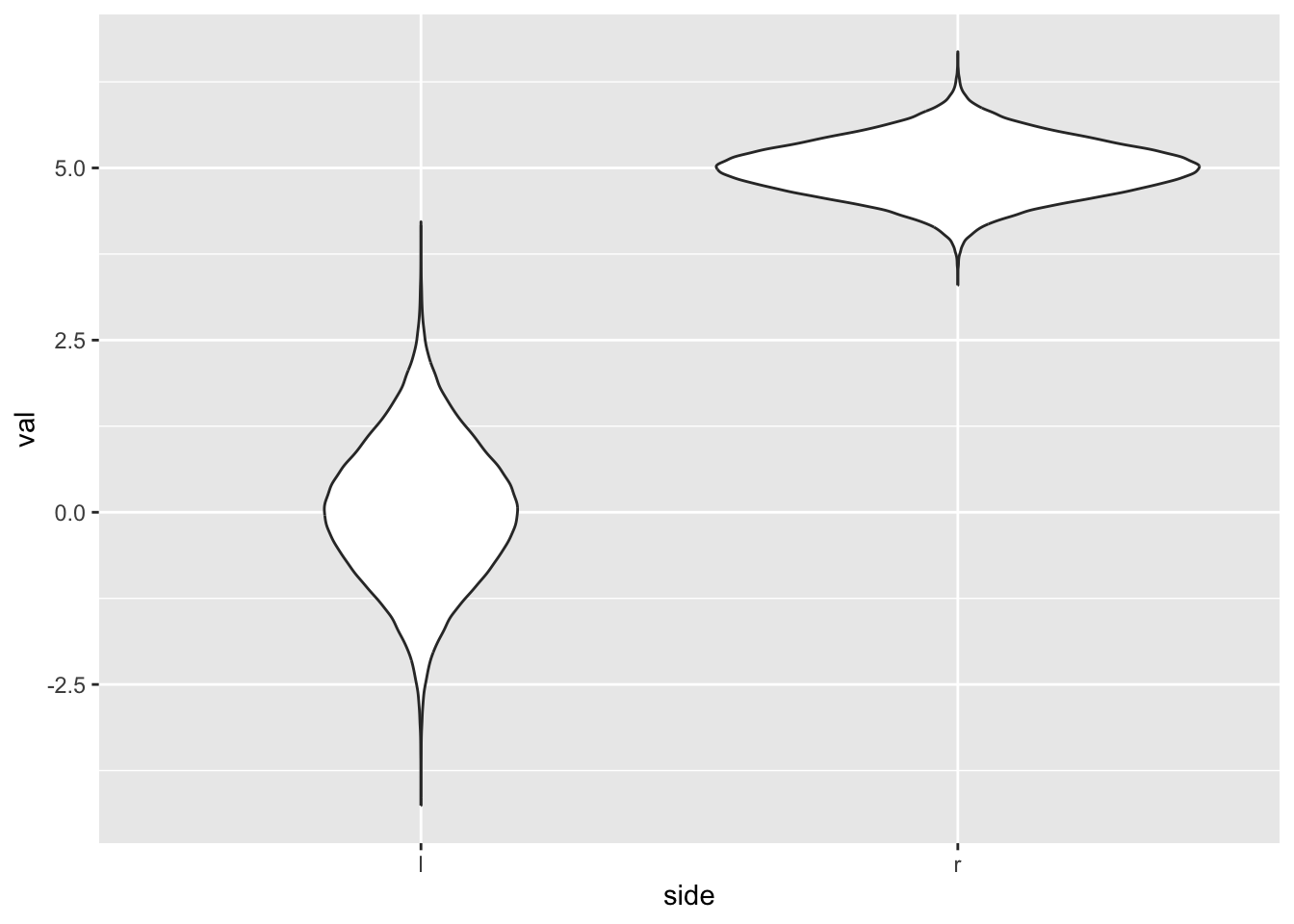
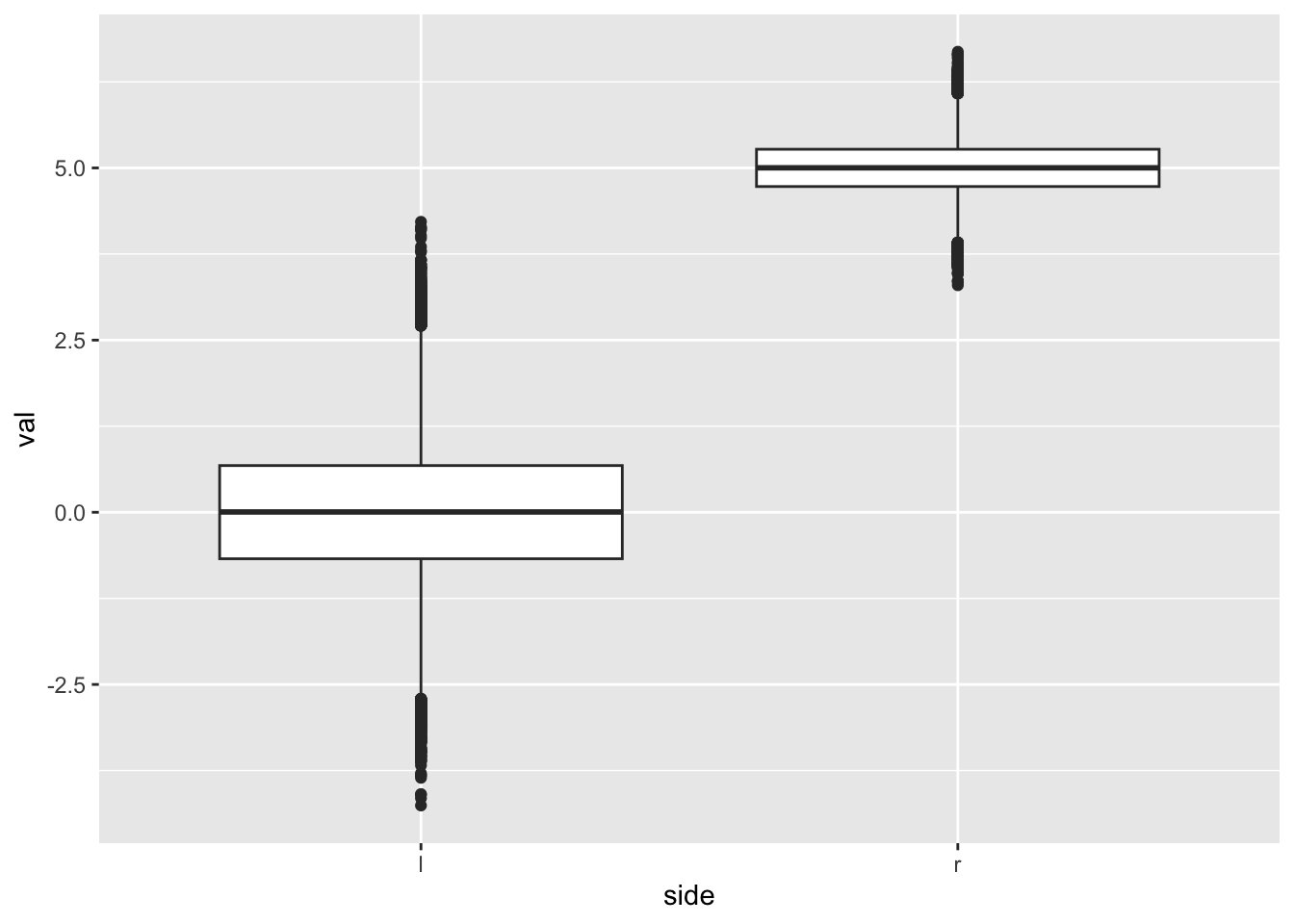
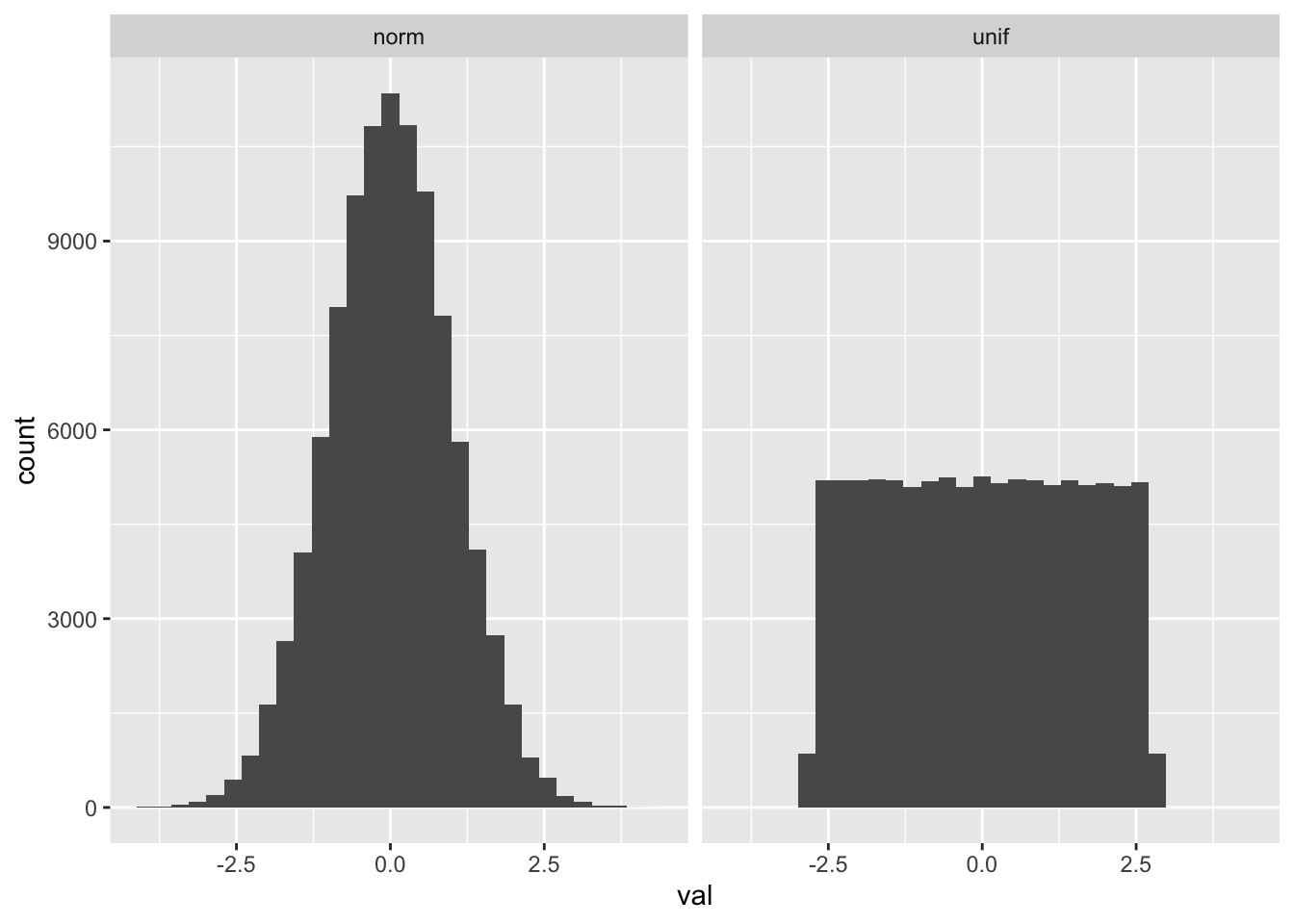
To replicate the side-by-side histograms in ?@fig-dual-histograms-matplotlib, we do the following:
A collection of special commands for doing specific things.↩︎
Source Code
---title: "Plotting with ggplot2"format: html---## About {-}This section describes some ways to generate plots using the R package [`ggplot2`](https://ggplot2.tidyverse.org).## Why R {-}R is a programming language specialized for data analysis and visualization.## Background {-}`ggplot2` is a package^[A collection of special commands for doing specific things.] for making 2D plots in R.It implements a special "language" for making plots based on the grammar of graphics suggested by @Wilkinson2005-do.That's where the 'gg' in the name comes from.In `ggplot`, we create a base plot, then add layers to it using a plus sign `+` operator. ## Set-up {-}To check whether `ggplot2` is already installed, run the following chunk:```{r}# The require() function returns TRUE if ggplot2 is installed and FALSE if it is not. The exclamation point symbol ('!') turns FALSE into TRUE and TRUE into FALSE. So, `!require(ggplot2)` will be TRUE if require(ggplot2) is FALSE. When this occurs, the `install.packages(ggplot)` commands runs and installs ggplot2.if (!require(ggplot2)) {install.packages(ggplot2)}```## Plotting one variable {-}### Discrete/nominal {-}First, we make some data.We store two variables, `category` and `value` using the `data.frame()` command.A data frame is a convenient, spreadsheet-like structure for storing data.```{r}data_random_discrete <-data.frame(category =c('ab', 'xy', 'mn', 'qp', 'ea', 'f2','gg', 'h*'),value =c(4.8, 5.5, 3.5, 4.6, 6.5, 6.6, 2.6, 3.0))```Here we create a data frame and give it the name `data_random_discrete`.You can choose any name you want, subject to R's restrictions on naming things.I try to use descriptive names.The data frame name suggests that we have a random, continuous variable (`value`) and a discrete or categorical variable (`category`).The data frame command stores the variable names along with the data.We can see this by using R's `names()` command:Sometimes it's useful to look at the _structure_ of something using the `str()` command.```{r}str(data_random_discrete)```Now that we have some data, let's plot it.#### Barplot {-}The following code makes a barplot.I'll explain what's going on after we look at the plot.```{r}#| label: fig-barplot-ggplot2#| fig-cap: "A bar plot of our random data."data_random_discrete |>ggplot() +aes(x = category, y = value) +geom_col()```This code sends the data frame (`data_random_discrete`) to the `ggplot()` function using R's pipe (`|>`) command.::: {.callout-note}## Many ways to say the same thingLike most (all?) programming languages, or really all languages, there are many ways to say the same thing.I like using the pipe `|>` command because it makes the code a little easier for *people* to read.:::The `ggplot()` function needs to know what data to plot, so this code ```rdata_random_discrete |>ggplot()```tells `ggplot()`, "Hey, ggplot, create a plot with data from `data_random_discrete`."An equivalent way to say the same thing is to assign `data_random_discrete` to ggplot's `data` parameter, like this:```rggplot(data = data_random_discrete)```In fact, R turns the code above that uses the pipe into this format.Now, running `ggplot()` alone like this doesn't actually create a plot we can see.We have to tell `ggplot()` what variables to plot and what kind of plot to create.In the graphics grammar `ggplot()` understands we add information to the plot using the plus `+` character.We tell `ggplot()` which variables to use by using the aesthetics `aes()` command.```rggplot() +aes(x = category, y = value)```Then, we add a graphic object or 'geom' to the plot.```aes(x = category, y = value) +geom_col()```There are different types of geoms for different types of plots.You can think of each geom as a way to map data to graphic elements.If the variable we want to plot contains the *values* we care about plotting, then we use `geom_col`.A column plot is just a type of barplot.Here, we have a *categorical* variable imaginatively named `category` and a *continuous* variable named `value`.See how the plot maps our category variable to the X axis and the value variable to the Y axis?That's the essence of making plots using `ggplot()`.We give `ggplot()` a data frame.Tell it which variables to assign to which aesthetics (properties of the plot).Add one or more geoms to make something we can see.To break this down even further, the following code shows a way to make a plot step-by-step.This can be useful when you're trying to figure out how you want to plot something.We'll explain the code first then run it.```rp <-ggplot(data = data_random_discrete) # <1>p # <2>```1. Make a ggplot with `data_random_discrete` as the data.frame; give it the name `p`.2. Show `p`.```{r}#| label: fig-blank-ggplot#| fig-cap: "A 'bare bones' plot with data, but no aesthetics or graphics." p <-ggplot(data = data_random_discrete)p```Notice that the plot is blank.The blank plot isn't very useful, so we have to add information to it about what variables we want to map to which *aesthetic* properties of the plot.The following code shows how this is done.```rp_aes <- p +aes(x = category, y = value) # <1>p_aes # <2>```1. "Add" aesthetics to `p` that assign the values in `category` to the x axis and values in `value` to the y axis. Give the combination the name `p_aes`.2. Show `p_aes`.The following results when we run the code:```{r}#| label: fig-ggplot-w-aes#| fig-cap: "A plot with aesthetics mapped to the X and Y axes but no other graphic elements."# Add aestheticsp_aes <- p +aes(x = category, y = value)p_aes```Now the plot has axes, but no data points.We need to add a *geom*.Geoms are mappings between data and visual graphic elements.Let's explain how to do that, then show the result.```rp_col <- p_aes +geom_col() # <1>p_col # <2>```1. Add to `p_aes` a geom called `geom_col()`, a column or bar plot. Assign the combination to a new variable called `p_col`.2. Show `p_col`.```{r}#| label: fig-ggplot-data-aes-geom#| fig-cap: "A complete plot with data, aesthetics, and a geom"p_col <- p_aes +geom_col()p_col```That looks good.Let's add some color to the bars.We do this by mapping the `category` variable to the `fill` property.```{r}#| label: fig-ggplot-ggplot-data-aes-geom-fill#| fig-cap: "Adding an aesthetic based on 'category' to fill the bars with color."p_colors <- p_col +aes(fill = category)p_colors```We can wrap all of this up in a nice little sequence of code as follows:```{r}#| label: fig-complete-ggplot-figure#| fig-cap: "The same figure generated from a short sequence of commands."data_random_discrete |>ggplot() +aes(x = category, y = value, fill = category) +geom_col()```Note that the category variables on the horizontal axis print in *alphabetical* order.Sometimes that might be what we want.But, what if we want to follow best practice and sort the bars in numeric order?There are several ways to to this (see <https://r-graph-gallery.com/267-reorder-a-variable-in-ggplot2.html>), but the way shown below uses the `forcats` package to 'mutate' or change the 'category' variable into one that is reordered by the 'value' variable.Note that the default is to sort in *ascending* order.```{r}#| label: fig-ggplot-sort-ascending#| fig-cap: "The same plot but with the columns ordered by 'value'."#| library(forcats)library(dplyr)data_random_discrete |>mutate(category =fct_reorder(category, value)) |>ggplot() +aes(x = category, y = value, fill = category) +geom_col()```To reverse the order from ascending to descending, the default, we use the `desc()` function to sort value from highest to lowest value, as in the following:```{r}#| label: fig-ggplot-sort-descending#| fig-cap: "The same plot but with the columns ordered by 'value' in descending order."#| data_random_discrete |>mutate(category =fct_reorder(category, desc(value))) |>ggplot() +aes(x = category, y = value, fill = category) +geom_col()```::: {.callout-note}## Your turn1. What would we need to do to make the `category` variable *ordinal*? 2. Why do we think that `value` is *continuous*?:::### Continuous {-}First, let's generate some random data.```{r}# Set a seed for our 'random' number generatorset.seed(19680801)n_values <-100000data_random_norm <-data.frame(val =rnorm(n = n_values, mean =0, sd =1))```#### Histogram {-}```{r}hist_1 <- data_random_norm |>ggplot() +aes(x = val) +geom_histogram()```What the code is saying is this: Send `data_random_norm` to `ggplot`; make the plot and its various layers; then give the plot a name (`hist_1`) so we can use it later. Like now, for instance:```{r}#| label: fig-histogram-ggplot2#| fig-cap: "A simple histogram"hist_1```To replicate the side-by-side histograms in @fig-dual-histograms-matplotlib, we do the following:Make two random data sets that differ slightly.```{r}x1 <-rnorm(n = n_values, mean =0, sd =1)data_random_norm_2 <-data.frame(side =c(rep('l', n_values), rep('r', n_values)),val =c(x1,0.4* x1 +5))```Then plot the data.```{r}#| label: fig-dual-histograms-ggplot2#| fig-cap: "Side-by-side histograms of two random (normal) sets of data."hist_2 <- data_random_norm_2 |>ggplot() +aes(x = val) +geom_histogram() +facet_wrap(vars(side), ncol =2)hist_2```#### Violin {-}```{r}#| label: fig-dual-violin-plots-ggplot2#| fig-cap: "Side-by-side violin plots of two random (normal) sets of data."violin_2 <- data_random_norm_2 |>ggplot() +aes(x = side, y = val) +geom_violin()violin_2```#### Boxplot {-}```{r}#| label: fig-dual-boxplots-ggplot2#| fig-cap: "Side-by-side violin plots of two random (normal) sets of data."boxplot_2 <- data_random_norm_2 |>ggplot() +aes(x = side, y = val) +geom_boxplot()boxplot_2```## Comparing distributions {-}Let's see how these plots can help us see when the distributions *differ* by more than just magnitude or standard deviation.```{r}# Normal "bell"-shaped like beforex_norm <-rnorm(n = n_values, mean =0, sd =1)# Uniform-shapedx_unif <-runif(n = n_values, min =-2.75, max =2.75)data_random_2 <-data.frame(side =c(rep('norm', n_values), rep('unif', n_values)),val =c(x_norm, x_unif))``````{r}#| label: fig-dual-histograms-diff-ggplot2#| fig-cap: "Side-by-side histograms of two random sets of data with **different** distributions."hist_2_diff <- data_random_2 |>ggplot() +aes(x = val) +geom_histogram() +facet_wrap(vars(side), ncol =2)hist_2_diff``````{r}#| label: fig-dual-violin-plots-diff-ggplot2#| fig-cap: "Side-by-side violin plots of two random sets of data with **different** distributions."violin_2_diff <- data_random_2 |>ggplot() +aes(x = side, y = val) +geom_violin()violin_2_diff``````{r}#| label: fig-dual-boxplots-diff-ggplot2#| fig-cap: "Side-by-side box plots of two random sets of data with **different** distributions."boxplot_2_diff <- data_random_2 |>ggplot() +aes(x = side, y = val) +geom_boxplot()boxplot_2_diff```## Plotting two variables {-}::: {.callout-warning}This page is under construction. Many components are missing.:::### Scatterplot {-}A scatterplot is a great way to compare two continuous variables.```{r}scatter_data <- tibble::tibble(norm = x_norm,unif = x_unif)scatter_data |>ggplot() +aes(x = x_norm, y = x_unif) +geom_point() ```